必备常识
按 Ctrl+F 以搜索关键字,如果找不到则点击“打印支持—同步展开所有内容”按钮再搜索。
性能是什么
主要分为处理速度/算力和数据传输速度/带宽,部分情况下还注重操作响应速度/延迟。播放视频时,画面卡顿问题往往来自于某一处的带宽不足(如网速、硬盘带宽);而另一种情况下,如果让性能太弱的 CPU 播放高度压缩后的视频,那么即使带宽充足,视频也会因为算力不足而卡顿。
电信号从储存介质到 CPU 核心的距离,以及使用的数据传输协议会导致巨大的延迟差异。在此之上还有因为同步,分阶段读取,安全检查,纠错校验等行为而积微成著:
| 数据位置 | 读取 CPU 周期 | 估计用时 |
|---|---|---|
| L1 缓存 | 3 | 1 ns |
| L2 缓存 | 10~20 | 3~7 ns |
| L3 缓存 | 30~70 | 10~25 ns |
| 内存 | 180~360 | 60~120 ns |
| 固态硬盘 | 240,000~900,000 | 80~300 μs |
| 机械硬盘 | 41,000,000 | 14 ms |
| 互联网 | 240,000,000 | 80 ms |
读写性能(IO)
硬盘或闪存芯片上的数据写入速度普遍比内存慢得多,但容量大且断电不丢失,是本地读写性能的主要瓶颈。实际读写性能通常分为两类,其性能差异相当于一次 vs. 成千上万次操作的区别。
- 连续读写:适用于大文件,速度快
- 随机小文件读写(4K 性能):每个文件至少占 4KB 空间,产生大量额外的寻址,速度可能只有前者的两成
注:视频属于大文件,而封装格式将音轨、字幕等数据紧密存放,从而避免了额外的随机读写,优化了性能。
数据(Data)是什么
一句话就是一段数据。计算机上的数据由电信号构成,分为模拟(电压代表大小)和数字(0、1 代表开关)两种。通过将计算机编程,人们根据不同的 0、1 长度以及组合,为 CPU 定义了操作内存、硬盘等存储设备的(读写)能力,从而使得更上层的操作系统和程序能够定义和使用更抽象化的数据(如坐标,像素值)等形式,才得以让电脑显示画面,播放视频。
元数据(Metadata)
描述数据的数据,例如零食的包装袋上会印有零食的参考图和名称。如果所有的包装都是白色,那么用户就无法找到想吃的零食。而电脑只能根据每个格式元数据(一般为文件后缀名)预设的“默认程序”来打开视频文件(设置错误时,也强行让设定的程序打开),而视频播放器也需要编码格式、亮度、对比度、帧率等元数据才能正确的播放视频。
压缩是什么
克劳德·香农在 1948 年的论文中定义了信息熵(Entropy)的概念,这代表了信息能被无损压缩到的理论极限,而“熵”也代表了丢失后无法被恢复(不可逆)的性质;依此,压缩就有了“有损”和“无损”两类的定义:
- 无损压缩:保留“熵”的前提下,剔除“冗余”,可复原
- 有损压缩:舍弃“熵”以实现更高压缩,无法复原
注:冗余是名词和形容词,但不是动词
压缩手段可以用“水果包装运输策略”来类比。农产品的成本以运为大,而“熵”在此就是不可逆的果肉状况:
| 📦 | 包装策略 | 信号处理 | 果肉状况 | 优劣原因 |
|---|---|---|---|---|
| 未压缩 | 连枝带叶,散装运输 | 原始采样 | 原汁原味 | 体积极大,密度低 |
| 无损压缩 | 清理枝叶,集装运输 | 数据去重与打包(如 ZIP) | 等同未压缩 | 体积巨大,密度低 |
| 有损低压 | 去皮去核,制成罐头 | 剔除不易察觉的内容再打包 | 有损但保留风味口感 | 体积大,密度中等 |
| 有损高压 | 榨汁装瓶 | 剔除可见内容与细节后打包 | 结构性损毁,仅剩液体 | 体积中等,密度高 |
| 全损高压 | 制成冲剂 | 剔除大部分内容再打包 | 全损 | 体积小,密度最高 |
编解码是什么
- 编码 Encoding:数据格式的转换。压缩取决于使用的编码器以及选择的模式
- 解码 Decoding:将被压缩的信号还原以播放的解压缩
- 软件解码 Software Decoding:以通用电路播放流文件,通常兼容性更高,画质更好,能耗/发热更高
- 硬件解码 Hardware Decoding:以专用电路替代软解,通常兼容性更低,画质更差,能耗/发热更低
- 如 libmfx,opencl,MMAL,direct3D
- 软件编码 Software Encoding:以通用电路编码流文件,压缩功能通常更完整可控,更慢,能耗/发热更高,同码率下的画质更高或最高
- 通用计算电路:CPU 核心、(高端采集卡中的)FPGA 核心、显卡的 CUDA/ROCm/OpenCL 单元
- 硬件编码 Hardware Encoding:以专用电路编码流文件,通常功能更少,速度更快,发热更低
- 如 NVENC,MMF/Venus,Intel QSV,AMD AMF,Elgato
封装与解封装——(De-)multiplex
- 将多个文件真正合并为一个文件,如 .zip .rar 格式的作用之一
- 信号处理中,电台/电视台将多路音频/视频流“封装调制”为一段模拟信号的处理方法
- 接收端通过对齐特定接收频率来接收其中一路信号
封装文件记录了视频帧率、音视频同步、色彩标识等关键元数据,播放器根据它们选择和配置解码器。常见的封装文件有:
| 📦格式(全称) | 用途 | 特点 |
|---|---|---|
| MP4 (MPEG-4 Part 14) | 网络与本地播放 |
|
| MKV (Matroska Multimedia Container) | 本地播放、多音轨/多字幕内容、实时录制 |
|
| MOV (QuickTime File Format) | 本地播放、视频编辑 |
|
| M4A (MPEG-4 Audio) | 纯音频存储、音乐播放 |
|
| FLV (Flash Video) | 网络与本地播放、实时录制 |
|
| M3U/M3U8 (MPEG URL Playlist) | 定义播放列表(本地媒体、流媒体,如 HTTP Live Streaming) |
|
| TS (MPEG Transport Stream) | 广播电视、流媒体传输、录制 |
|
视频编码专利
常见的有核心技术专利(特定编码步骤、装置设备具体实现等应用)、标准必要专利(即构成 AVC、HEVC、AV1 等编码所需的专利)、免费开放许可等。由于涉及视频编码的专利/权利人多,因此一种视频编码是由多项专利打包的专利池所构成,由专利池管理公司运营。
HEVC H.265 的专利许可最初成分混乱且昂贵,与 AVC H.264 的许可截然不同。主要的专利池包括:
- HEVC Advance:包含三星、高通、GE、杜比等公司的专利
- MPEG LA:包含来自三菱、日本广播协会 NHK、JVC Kenwood、苹果等公司的专利
- Velos Media:包含来自爱立信、松下、索尼等公司的专利
...以及独立的专利权持有方许可(约占 38%,如诺基亚的 HEVC 标准必要专利集)才能合规使用(更不如不用)。
图:Windows 文件管理器预览 HEVC 编码视频、HEIF 图像的组件,定价 $0.99 USD。通过让用户支付这笔费用。
微软以“产品默认不包含”而绕过了 HEVC 的专利费。
比特(Bit)是什么
- 二进制:3 位数的所有排列组合是 000~111,共 8 种可能的状态/值,若增加到 4 位,则会得到 0000~1111,共 16 种可能
- 十进制:3 位数的所有排列组合是 000~999,共 1000 种可能的状态/值,若增加到 4 位,则会得到 0000~9999,共 10000 种可能
能够准确描述这一随位数增减状态数量的方法就是“底数的幂”;比如以二进位,共 3 位,就是 \( 2^3 \);以十进位,共 3 位,就是 \( 10^3 \)。
为了简化,统计学家约翰·图基在备忘录中把“binary digit”缩写为“bit”,因此“二进制 3 位数”被称为 3 bit;“二进制 4 位数”被称为 4 bit。
数据大小单位
- bit(比特):最小的计量单位,\(1 \text{bit} = \frac{1}{8} \text{Byte}\),衡量传输流量
- Byte(字节):\(8 \text{bit} = 1 \text{Byte}\),衡量文件大小
二进制千进位(准确)
- kibi-bit(Kb,千比特):1024 比特,210
- kibi-Byte(KB,千字节):1024 字节,210
- mebi-bit(Mb,兆比特):10242 = 1048576 比特
- mebi-Byte(MB,兆字节):10242 = 1048576 字节
- gibi-bit(Gb,吉比特):10243 = 1073741824 比特
- gibi-Byte(GB,吉字节):10243 = 1073741824 字节
十进制千进位(模糊)
- kilo-bit(Kb,Kib,千比特):1000 比特
- kilo-Byte(KB,KiB,千字节):1000 字节
- mega-bit(Mb,Mib,兆比特):10002 比特
- mega-Byte(MB,MiB,兆字节):10002 字节
- giga-bit(Gb,Gib,吉比特):10003 比特
- giga-Byte(GB,GiB,吉字节):10003 字节
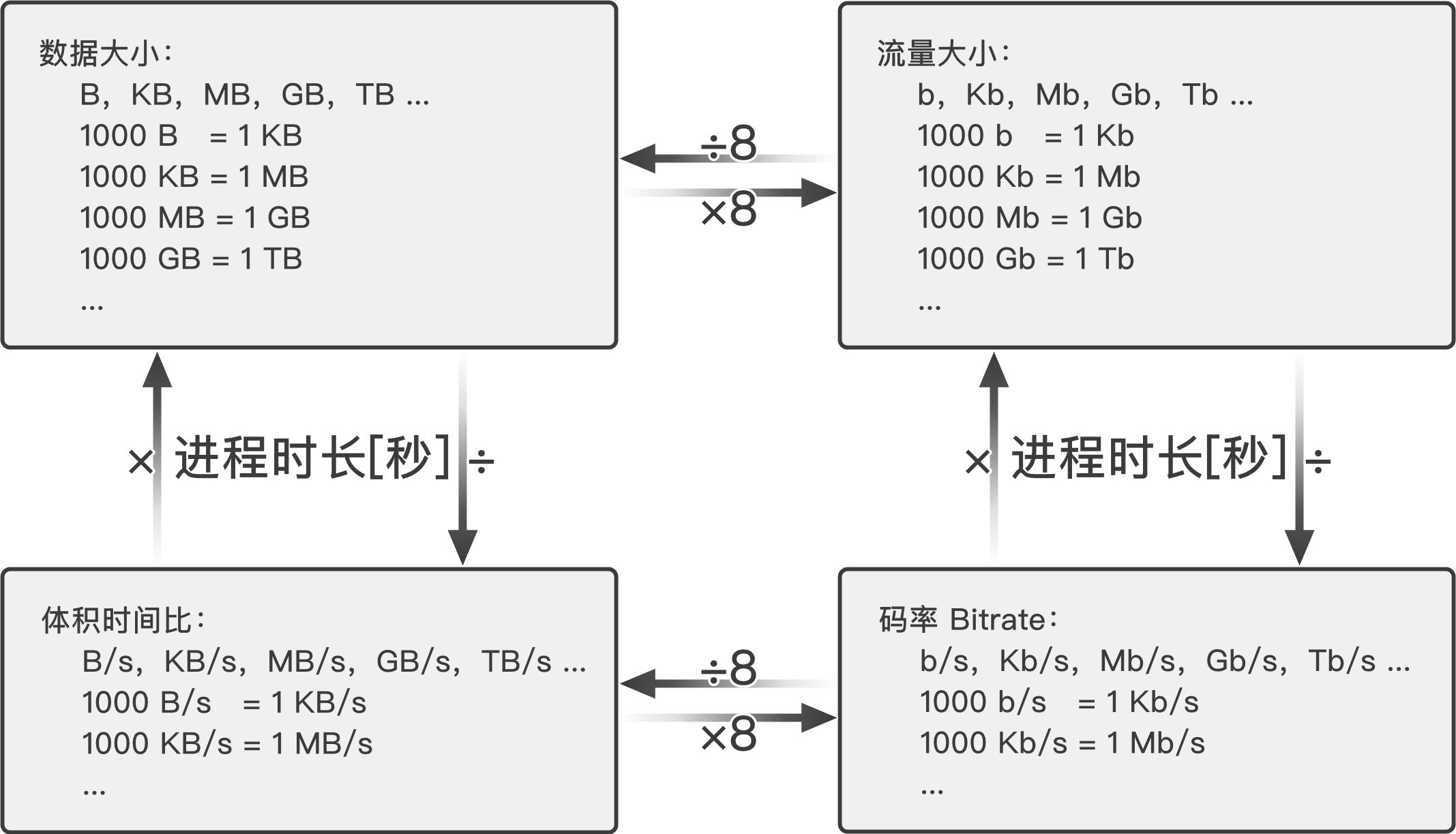
图:比特,字节与体积时间比的转换
操作系统(处理器、内存)的“字节”是以二进制换算的,而储存容量(闪存、硬盘)的“字节”是十进制换算的。一开始储存容量不大,而 1000 进和 1024 进差 2.4%,不如多卖电脑重要,就有了现在不统一的容量称呼
- 使用十进制表示数据和容量大小除了不准确外,还是会比二进制方便很多
- Mac OS X 10.6 开始整个系统都以十进制表示大小
- 为了兼容,Windows 系统的单位可能永远都不会改
码率/比特率(Bitrate)
文件体积每秒,单位 bps,Bps,Kbps,KBps,Mbps,MBps,Gbps,GBps 等。“ps”即 per second,也可写作“Kb/s,Mb/s”等。
- 长 1 分钟,10MB 大小的视频文件的平均码率为\( (10 \div 1 \times 60) \times 8 \text{bit} = 1333.3 \text{Kbps} \)
- 同样 10MB 的视频下载 1 分钟,平均下来网速即\( \frac{10}{1 \times 60}=166.67 \text{KBps} \),\( 166.67\times 8 \text{bit} = 1333.33 \text{Kbps} \)
- 这里的 ÷1 代表缩放到一分钟范围,×60 代表缩放到一秒,×8bit 代表 1 Byte 转 8 bit。
存储技术带宽(Storage Bandwidth)
视频属于大文件,写入和读取操作属于几乎不存在随机读写性能的连续大文件读写。因此写入视频的速度可以直接按照硬盘的连续写入带宽/速度看待:
- PCIe 4.0x4 SSD:约 63Gbps(8GBps)
- PCIe 3.0x4 SSD:约 31Gbps(4GBps),同时也是 PCIE 4.0x2 SSD 带宽
- 3840x2160x120 未压缩 RGB 3×8bit 视频流(120 fps):约 24Gbps
- 3840x2160x90 未压缩 RGB 3×8bit 视频流(90 fps):约 18Gbps
- 3840x2160x120 无损压缩 YUV 8bit 视频流(估计):
- 4:2:0:≈ 7.2 Gbps
- 4:2:2:≈ 9.6 Gbps
- 4:4:4:≈ 14.4 Gbps
- SATA3 SSD:有效带宽约 4.8Gbps
当然,24Gbps 的写入量太过夸张,只要 300 多秒就会写满 8000Gb(1TB)的空间,这个大小也注定与网络传输无缘了。
注:固态硬盘实则数据详见 TomsHardware。
色彩
人眼感光细胞捕获特定强度的电磁波(可见光),然后通过大脑处理,产生了我们所看到的幻觉。实际上,色彩只有一个标量属性,即频率。
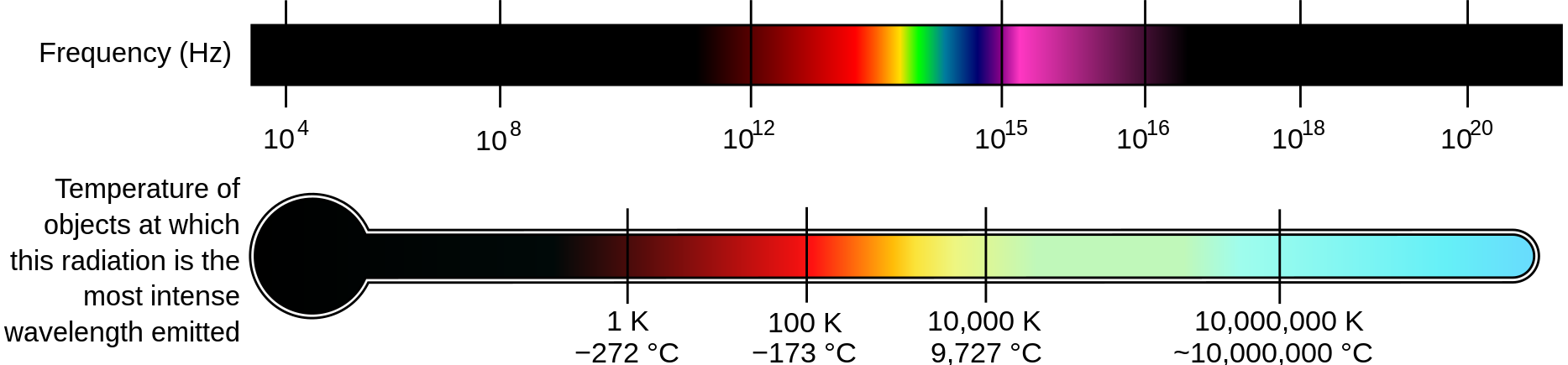
图:色彩的波形频率变化,见维基百科。
亮度
- 物理亮度:可见光电磁波的强度或振幅,以流明 lumen/lm,坎德拉/烛光 candela/cd,或尼特 nits/cdm2 计量:
- 1cd/lm 大约为一支蜡烛的亮度
- 由于能量(电压、焦耳)与亮度正相关,所以往往被直接称为 i“能量”
- 尼特(nit)代表 1cd 光源投射到一平方米(一般情况下距离一米)区域后所剩的亮度,主要用于显示器的亮度设定
- 一般来说 \(1 \text{nit} \approx 3.426 \text{lm}\),但实际的“汇率”取决于光源和测量仪器/方法
- 或者更干脆一点,两者量纲不同,不能相对比
- 软硬件亮度:代表灰度像素值的大小,值越大表示像素点越亮,但最大亮度受硬件和用户设定限制。伽马 gamma/Y 值定义了像素的亮度范围,最小值 0 为黑色
YUV / YCbCr 色彩空间图像的亮度平面 Y,或者 RGB 图像分离出的亮度/灰度平面,有时也被称为伽马平面或 Y 平面。
灰度/灰阶 Grayscale
代表将色彩信息去除,只保留黑、灰、白色的单通道图像。
硬件位深/色深(Bit/Color Depth)与范围(Color Range)
对应电压的缩放值。由显示器的驱动板/主控板接收 GPU 输出的数字信号,并转义为像素点的电压得到。因此使用了 CRT 显像管的电视可能是模拟电视,也可能是数字电视,取决于有没有如 HDMI,DisplayPort 等数字信号接口。
注:“色深”是衍生叫法,“位深”是严谨称呼;并没有“色彩深度”等其它含义。
有限位深(Limited/Analog/TV)
模拟电视使用了 \( 0 \text{mV ~ } 700 \text{mV} \) 的输入电压表示位深,对应软件的完整位深。但为了传输同步脉冲信号和消隐信号,就分别拿走了 0~15 和 236~255 两个范围,即流传至今的“有限范围”(Limited Range)。
到了数字时代,电视厂商都使用 HDMI 协议的显示信号接口,电脑厂商则使用 DisplayPort 的显示信号接口,所以在“电脑接电视”,和“游戏主机接显示器”时往往需要额外的输入和输出设置,才能得到明暗过渡正常的画面。
- 一般在显示器的 OSD 设置界面上看到,写作兼容/有限/模拟/电视范围
- 一般来说,数字显示器/数字电视应该是原生支持设置为输入完整位深的,若没有则可以通过设置 HDMI Black Level 来缩放到正常明暗过渡
软件的位深与范围
数字位深的分阶用位/bit 表示。如四位 4bit(16 单位)\(2^4\)、八位 8bit(256 单位)\(2^8\)、10bit(1024 单位)\(2^{10}\) 的形式表示。
- 8bit 位深最大值/纯白色为 255(
0xFF) - 10bit 位深最大值/纯白色为 1023(
0x3FF)

图:完整/PC 位深(Full)与有限/TV 位深(Limited),包括上述说明的更优版本见硬件茶谈。
位深转换的错误
有限转完整
- 设备:设置为输出有限范围
- 显示器:设置为输入完整范围(默认)
- 结果:显示器缺失最暗和最亮的范围,呈现灰蒙蒙的画面
该错误常见于电脑用 HDMI 线连接电脑显示器,应纠正显卡输出设置或使用 DisplayPort(DP)接口。
完整转有限
- 设备:设置为输出完整范围
- 电视:设置为输入有限范围(默认)
- 结果 1:位深为 8bit 时,0~15 和 236~255 的亮度范围被丢弃
- 结果 2:位深为 8bit 时,16-235 的亮度范围被强行拉伸,使得画面过亮且过暗(饱和度过高)
古老 / 低成本的 HDMI 电视只支持有限范围,PC/Xbox/PlayStation 设置为输出完整所致。
默认配置错误
一些媒体使用了被淘汰的色彩空间编码,导致该媒体被人或程序误判为老格式——有限位深;例如 yuvj 这个 ffmpeg 用过但已淘汰的色彩空间(实际上这是完整位深,这里的 j 是指 jpeg)
新兴的一些摄影图片格式,如 heic、avif 等可能会遇到兼容性问题,包括部分手机相册转换错误,以及 Windows 图片浏览器的显示错误
内容位深
即图像和视频储存时使用的色彩空间位深。
为什么 10bit 位深的内容少见
注:此段在当下语境中有些超纲,但该疑问本身很常见。
10bit 位深的视频内容的确能被压缩到比 8bit 位深体积更小,同时画质更好的程度;但这需要满足以下条件:
- 视频源至少是 10bit 编码,或者使用了大量滤镜来修复
- 视频编码器必须用慢速、精确的帧间搜索冗余,否则压缩率不但不提升,还有可能会下降
- 播放器需要为高位深内容增加缓冲区大小以储存解码内容,否则容易卡住,但则会极大影响低网速的情况
同时,10bit 位深的图片往往 8bit 位深的同一张图片大,尽管它们在解码后/未压缩状态的大小差距在 20% 左右(1920x1080 YUV4:2:0 格式)。不过在现代图片编码器(HEIC/AVIF)中,这个差距也有可能会被追平。
| 🎆格式 | 分辨率 | ~比特数 | ~字节数 |
|---|---|---|---|
| YUV420 8bit | 1920×1080 | 24.88 Mbit | 3.11 MB |
| YUV420 10bit | 1920×1080 | 31.10 Mbit | 3.89 MB |
至于老设备不支持的情况反而不是问题,因为厂商正愁自己的用户暂无升级之由,而会积极推动各种格式(如 HDR、杜比视界)的普及,而“服务定制”对于互联网来说也是老生常谈了。
伽马曲线/伽马映射
- 生理伽马映射:人眼对于亮度的感知与物理亮度的线性变化所异
- 人眼敏感于低至中等亮度的变化,而对中高亮度的变化则相对不太敏感。因此,当内容的亮度变化呈直线关系时,人眼会感觉到“发黑”
- 许多游戏的初始设置中,“将滑块调节到能清晰看到左侧暗部图像”实际上就是在调节生理伽马曲线
- 相机 CMOS 捕获的线性亮度(RAW 直出)在人眼看来会显得“发黑”,需要“白化”校正
- 软硬件伽马映射:屏幕电压与线性亮度变化之间的关系并非线性
- CRT 显示屏一般需要放大电压到 \( v^{2.2} \) 才能够直线地显示亮度变化
- sRGB 标准则因为 CRT 显示器的物理特性自带约 2.2 的伽马值会导致画面“黑化”,因此在录制过程中,相机才需要预先对图像进行伽马校正“白化”处理:\( \gamma^{\frac{1}{2.2}} \)
- 若编辑 RAW 直出图像的软件未打开 Adobe 软件默认关闭的“按伽马系数混合 RGB 颜色,伽马值为 1”的设定,图层透明通道之间的过渡会显得杂乱不堪。

图:对亮度平面调整伽马映射,来源:developer.apple.com。
伽马矫正
两种方式:向上提亮缩放“白化” \( s = cr^\frac{1}{\gamma} \) 和向下变暗缩放“黑化” \( s = cr^\gamma \)。
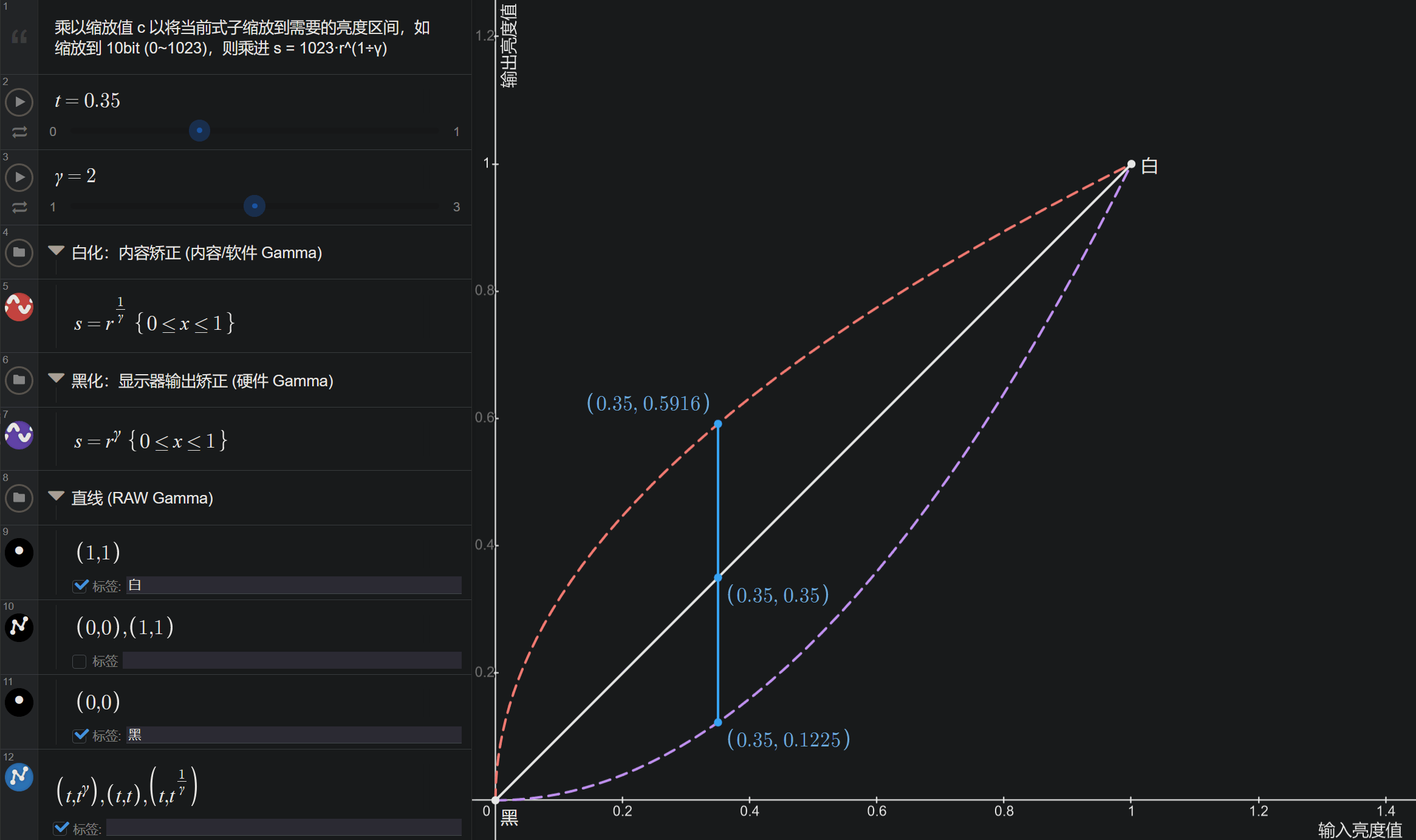
图:伽马矫正的指数算式,此处c = 1代表 0~1 的亮度区间,8bit 256 深则c = 256,见desmos 互动例。
对比度(Contrast)
任意量纲的间距。在图像与显示器中代表最亮~最暗的亮度差,音频中代表“动态范围(Dynamic range)”,对比度低的图像会“发灰”,因为当前的亮度设置位于这个灰度水平上;对比度高的图像会显得生动,因为显示出来的色彩往往更符合心理预期。

图:对比度。
饱和度(Saturation)
色彩饱和度(Saturation)的概念来源于光学和色彩学,表示色彩的纯度。有几分类似于化学溶解度,饱和度越高则图像越鲜艳,为零时得到灰阶图像;最大时得到纯色图像。对比度接近饱和度,但不是饱和度(从图中可见没有白色溢出)。

图:饱和度,来源:developer.apple.com。
像素(Pixel / pix / pel / px)
像素是组成图像的最小单位,决定了图像的物理大小和分辨率。一般情况下分为屏幕的硬件像素大小,和图片/视频的软件像素大小两种。当软件像素小于硬件像素时,显示 100% 大小的图片会变小,或者通过缩放滤镜将图片放大以适应屏幕。反之,若硬件像素大小小于软件像素,则会使用缩放滤镜将图片缩小至合适的尺寸,或者图片会溢出屏幕。图像中的每个像素都有位置和颜色两份信息。
每英寸像素(Pixel Per Inch,PPI)
指屏幕或印刷设备上的物理像素密度,这取决于设计时预期的观看距离。屏幕的 PPI 高则适合近距离观看,因为物理像素更密集。在印刷设备的 PPI 越高,打印出的图像就越细腻。软件的 PPI 主要用于计算新建图像的像素大小和分辨率,以确保图像有着适当的大小和清晰度。
- 矢量图形通常不涉及 PPI 概念,因为它们以数学方式描述图像,可以无限放大而不失真
- 高 PPI 的显示器是一种较新的规格,旧的软件在这些显示器上会出现模糊,或界面过小的问题,见硬件茶谈

图:每英寸像素,来源:www.inchcalculator.com。
色彩空间(Color Space)
用于表示和处理图像颜色的数据格式,具有适用于各种不同应用场景的多种类型。最常用的是分为硬件和操作系统的 RGB 色彩空间,以及内容的 YUV/YCbCr 色彩空间。见 Captain Disillusion 的科普。

RGB 色彩空间由红色 Red、绿色 Green、蓝色 Blue 三个通道组成,每个通道的数值表示相应颜色的强度,对应着显示器红色 LED,绿色 LED 和蓝色 LED。常用于显示器、摄像头和图形处理等硬件和软件系统中。
YUV/YCbCr 色彩空间是另一种常见的色彩表示方式,用于存储和传输视频数据。Y 代表亮度 Luminance,而 U、V 代表色度 Chrominance。严格的说,YCbCr 特指数字信号,YUV 特指模拟信号,但由于后者字数更少且打字容易,所以现在常被混为一谈了。
| 🎆色彩格式 | 构成色 | 特点 | 存在原因 | 支持范围 |
|---|---|---|---|---|
| RGB | 红绿蓝 | 通用 | 使显示器/照相机通用 | 几乎所有可视媒体 |
| ARGB | α 红绿蓝 | 透明通道 | 便于图层化编辑 | 图片,部分视频 |
| CMYK | 湛 zhàn 洋黄黑 | 减法色彩 | 节约暗场彩色墨 | 打印纸 |
| YCbCr/YUV,YPbPr | 白蓝 - 黄红 - 绿 | 压缩 | 压缩视频图片 | 所有有损压缩 |
色度采样(Chroma Subsampling)
YUV/YCbCr 色彩空间下,利用人眼对色度细节不敏感的特性(见下图全分辨率和半分辨率的色度面),降低色度平面的分辨率,从而压缩图像。色度采样格式通常用三个数字表示,例如 4:4:4、4:2:2 等。编码时下采样,解码时上采样。
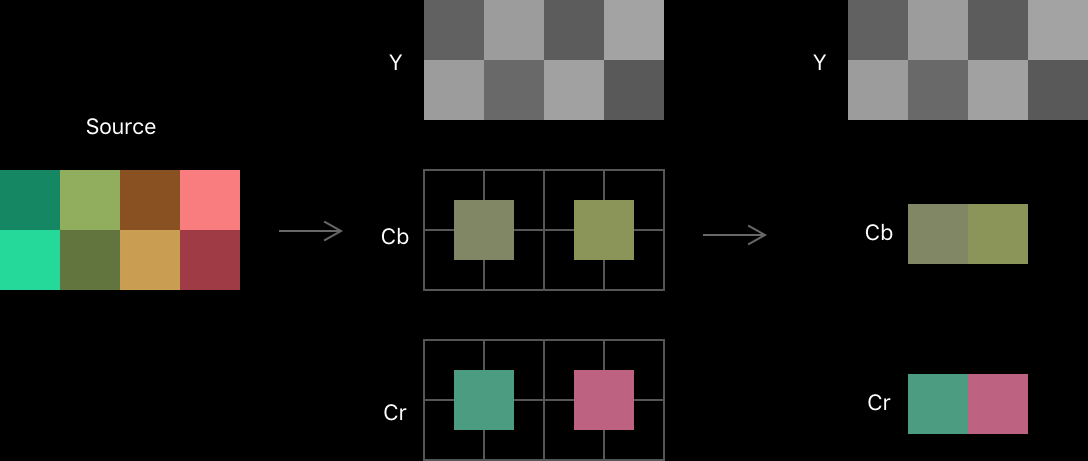
图:色度采样,来源:developer.apple.com。
A:B:C 代表微观分辨率下,每个长 A 像素,高 2 像素的空间,第一行缩到 B 个色度像素,第二行缩到 C 个色度像素。如 4:2:2 代表色度平面的每个 4x2 微观区间中,第一行的色度分量保留 2 个像素,第二行的色度分量也保留 2 个像素。色度采样详见下表:
| 👾采样 | 1920x1080 下宏观 | 色度 4x2 微观 | 特点 | |||
|---|---|---|---|---|---|---|
| 4:4:4 | 亮度,色度皆 100% 宽 100% 高(色度 1920x1080) | 色素 | 色素 | 色素 | 色素 |
视频滤镜可直接作用于亮度或色度平面, 而 RGB 色彩空间需要转过去、应用滤镜、再转换回来, 因此非常适合图像和视频编辑,并且便于压缩色度平面 |
| 色素 | 色素 | 色素 | 色素 | |||
| 4:2:2 | 亮度 100% 宽 100% 高,色度 50% 宽 100% 高(色度 960x1080) | 色素 ← | 色素 ← |
逐行扫描,色度像素靠插值放大补全。 由于人眼对色度变化不敏感,同时使用整数倍的缩小放大, 因此在提高压缩的同时除了边缘细节对齐误差外的损失可以忽略不计 |
||
| 色素 ← | 色素 ← | |||||
| 4:2:0 | 亮度 100% 宽 100% 高,色度 50% 宽 50% 高 960x540 | 色素 ← ↑ ⬉ |
色素 ← ↑ ⬉ |
|||
| 4:0:0 | 亮度 100% 宽 100% 高的灰度视频,或丢弃色度信息的图像/视频 | |||||
| 4:1:1 | 亮度 100% 宽 100% 高,色度 25% 宽 100% 高 480x1080 | 色素 ← ← ← ← | 交错扫描 Interlaced,横着扫描可以避免将上场、下场的像素混淆 | |||
| 色素 ← ← ← ← | ||||||
| 4:1:1-par4:3 | 亮度 75% 宽 100% 高,1440x1080 色度 18.75% 宽 100% 高,360x1080 | 色度像素 ←×5.333 | ||||
| 色度像素 ←×5.333 | ||||||
| 4:2:0-par4:3 | 亮度 75% 宽 100% 高,1440x1080 色度 37.5% 宽 50% 高,720x540 | 2.667 ← ↑ 2.848 ⬉ |
2.667 ← ↑ 2.848 ⬉ |
逐行扫描,非方形亮度像素,除了清晰度更低,色度像素在拉伸后也会出现更大的对齐偏差,曾被用于电视台和视频网站(有的横向有的纵向)压缩视频,现在基本已经绝迹 | ||

图:RGB 与 YCbCr 的转换,色度采样的使用及编解码与录制、传输和显示的关系
视频帧(Video Frame)
描述连续图片序列中的单张图片(随便拍一张图片不算,连拍算)。有帧大小、帧率/帧数、帧类型(关键帧,过渡帧)等描述规格,构成了图像内容运动的假象。
帧率(Frame Rate / Frames per second / FPS)
每秒刷新的图像帧数,越高则变化越流畅。不同的内容类型会根据视频标准,成本和艺术效果来选择一个合适的帧率来拍摄和制作。
流畅度(Fluidity)
在智能手机的发展阶段,有个叫一加的品牌率先推出了 90Hz 屏幕的手机,这使得系统流畅度首次被直观地体现,该手机也成为了当年的热门产品;而与此同时,电影、电视剧的 24fps 是流畅的、浏览器观看网页的 60fps 是流畅的、漫画材质动画的 23.976(24fps 丢帧)同样是流畅的;但第一人称射击电子竞技(e-Sport FPS)游戏选手纷纷放弃了更高分辨率的显示器,而是专门选购了 240~800Hz 的显示器,将游戏画质设置到最低,显卡升级到顶配,只为保证流畅。
同时,随着帧间插值(Frame Interpolation)技术所依赖的 GPU 神经网络变得足够快,便有许多人尝试对电影和漫画材质动画插帧,从而达到 60~120fps,然而结果不是充斥伪运动感的飘忽画面,就是因画面帧前后突变而产生各种鬼影;与此同时,使用 Live2D 动补技术的虚拟形象却在 60fps 帧率下活灵活现的显示。每一名虚拟主播都能轻松、自然地做到这种流畅,而插帧用户就像遭了天谴一样,无论怎么调参和增加算力都无可奈何。
流畅度的本质在于保证移动内容在帧时间单位上的准确性:帧率越低,移动物件的拖影/动态模糊越长和大,反之帧率越高,移动物件的拖影/动态模糊越短与小,甚至达到一定高帧率,或速度足够慢时,每一帧的物件应该与静止画面完全一致。
手机和显示器往往要快速滑动或平移大面积的内容,此它们的屏幕帧率自然是越高越好;录像电影和漫画材质动画尽管有着各自的成本与时限,但低帧率有低帧率的办法——因此电影会限制镜头平移速度(即电影运镜)、主动给高速物件添加动态模糊(摄影快门角度和速度/曝光时长);漫画材质动画会利用视觉暂留效应的一拍 N 作画,也会使用室内等移动物件少的场景,这才在更低的帧率下实现了对人眼来说足够流畅的画面,这种“已流畅”的画面是注定无法通过简单的插帧来优化的;只有少数情况下,漫画材质动画中偶尔出现的无动态模糊大范围背景平移才用得上。
恒定帧率、可变帧率(Constant / Variable frame rate)
恒定帧率代表每秒固定拆分为 N 帧,在视频播放和剪辑都最具兼容性。可变帧率技术则主要用于解决手机录像时的发热和耗电,因此妥协了软件兼容性。因此,录制视频时应根据设备的电量和散热能力进行选择,而录制需要剪辑的素材时则应选择恒定帧率。
小数帧率 / 丢帧、剪辑素材对齐问题
NTSC 模拟电视每个频道的标准带宽大约为 6MHz(但实际宽度仅为 4.5MHz)。接下来发生的事谁都没有预料到——彩色电视出现了。结果是原本的频宽完全放不下彩色电视台信号,而且由于电视机已经售出,不可能更改用户家里电视的频宽和扫描线的数量。最终解决方案是将原本的帧率除以 1.001(即 30 ÷ 1.001 ≈ 29.970029...)以保持与帧率的对齐(同时也引入了 YUV 4:2:0 色彩空间)。经过这般折腾,码率/频宽总算被压缩了下来,但后继影响了数字视频的丢帧帧率标准——为了与模拟电视兼容Reddit: GhostOfSorabji。

图:不同帧率的对齐问题,如果素材的帧率不统一就会出现的“快慢帧”问题,见Taran Van Hemert
在视频编辑中有时会遇到对齐“不同帧率”乘以“不同帧率种类”视频素材的困难问题,处理起来非常考验剪辑水平。但与其这样,不如一开始就商量好使用正确的录制设定就可以了。
逐行/交错扫描 Progressive / Interlaced
逐行扫描通过一行行从左到右地刷新像素来构建图像,是最为常用的屏幕刷新方式。交错扫描的方法不同,它使用 YUV 4:1:1 采样,将屏幕的奇数像素行视为一个场,偶数像素行视为另一个场。这两个场在录制时错开一定时间,这样在模拟电视上观看时会产生 60fps 的视觉效果。交错扫描的原理是为了节省模拟电视信号的频段区间(与收音机接收电台信号一样)。因此,通过在时间上分隔行来节省空间,可以几乎将每个频道的频宽减半,例如(\(525 \text{行} \times 30\text{fps} = 15.75 \text{MHz}\))。

图:NTSC,PAL 和 SECAM 播放规格的地区分布,见维基百科
音频格式(一维)
最简单的结构为——脉冲编码调制 Pulse-code modulation(PCM)信号。见维基百科。
| 🎶压缩 | 格式 | 音质 |
|---|---|---|
| 有损 | mp3,aac,ogg(vorbis/opus) | 取决于耳机/音响,混音,声场。分为 HiFi 音频和监听音频两种质量参考 |
| 无损 | flac,alac,ape,it | |
| 未压缩 | wav(PCM) |
图像格式(二维)
最简单的结构为 PCM 信号 + 每 n 个像素换行的元数据
| 📷压缩 | 格式 | 最大 RGB 位深 | 最大 YCbCr 位深 | 最大 CMYK 位深 | 动图 | HDR | 透明 |
|---|---|---|---|---|---|---|---|
| 有损 | jpg | 8 8 8 | 8 8 8 | 24 24 24 24 | |||
| 有~无损 | gif(编码无损,颜色少了) | 24×3 中取 8×3 | ✓ | 仅 1bit | |||
| webp | 8 8 8 | 8 8 8 | ✓ | ✓ | |||
| jpg-XR(兼容 jpg) | 32 32 32 | 8 8 8 | 16 16 16 16 | ✓ | ✓ | ✓ | |
| avif,heif/heic,filf | 32 32 32 | 16 16 16 | ✓ | ✓ | ✓ | ||
| 无损 | pdf,jpg-LS,png | 16 16 16 | 32 32 32 32 | 仅 mng | ✓ | ||
| 有损~无损~未压 | tif | 16 16 16 | 8 8 8 | 128 128 128 128 | ✓ | ✓ | |
| 未压缩 | raw,bmp | 24 24 24 | 仅 raw | ✓ | ✓ | ||
| dpx | 64 64 64 | 16 16 16 | ✓ | ✓ |
视频格式(三维)
最简单的结构为一组图片。
| 🎥压缩 | 格式 | RGB/YCbCr 位深 | HDR | 透明 |
|---|---|---|---|---|
| 有~无损 | qt,hevc,avc,vvc,vp8/9,DNxHR/HD,prores | 12 12 12 | 除 avc,vp8 | 仅 prores |
| 无损 | rawvideo | 32 32 32 | ✓ | |
| cineform | 16 16 16 | ✓ | ||
| 有损~无损~未压 | Flash 动画 | 内嵌图片决定 | ||
对比动图、视频、图片序列
图片与视频之间还有图像序列,动图两种中间格式。图像序列直接储存视频为大量图像,一般用于录制素材;动图如 .gif,.mng 则表面上和视频一致:
| 设计\格式 | 动图编码 | 视频编码 | 图片序列 |
|---|---|---|---|
| 播放用时 | 短(GOP = 1) | 长(GOP >= 1) | 无 |
| 帧率 | 随便 | 随便 | 随便 |
| 分辨率 | 随便 | 随便 | 随便 |
| 帧间冗余 | 一般不支持 | 一般都支持 | 无 |
| 需要封装 | 无 | 一般都需要 | 无 |
滤镜/滤波器 Filter 与滤镜工具
通常用于过滤水和净化空气。在信号中代表处理一维音频和二维视频信号的算法。滤镜工具代表能够将滤镜应用到信号上的软件或插件,比如 Adobe Premiere Pro,After Effects,ffmpeg,DaVinci Resolve,ScreenToGIF,FL Studio,Reaper,Ableton,Audition,GIMP,Photoshop,FSCapture,LightRoom,OpenCV 等编辑图像、视频和音频的工具。AviSynth(+)和 VapourSynth 严格上称为帧服务器,因为需要连接一个编码器才能导出视音频。
噪声 Noise 与颗粒 Grain
电影胶片(卤化银晶体)被投影灯放大得到胶片颗粒 Film Grain,在单独一帧胶片画面上是一种比较自然动态噪声。更广义且不自然的噪声来自于电视信号接收器或相机使用放大电路 amplifier 放大无信号频段,或黑暗场景产生的“雪花”画面和声音。以及根据厂家镀膜工艺水平而定的显示器屏幕磨砂表面“静态噪声”等等。
一般来说,如果噪点的边角尖锐,缺乏渐变,则是“难看的噪声”。另一种比较极端的判断方法是——只有影视导演亲手保留,或游戏美工专门根据显示技术适配处理过的噪声才是好看的噪声、由第三方私自添加的噪声是“难看的噪声”。
实际上,人眼的“成像技术”也决定了人看到的画面本来就有很多噪点,而且是动态噪点,只是未注意的时候都是大脑的实时降噪和幻觉在抑制而已。

图:正在放映 2023 年电影《奥本海默》的 70mm IMAX 胶片放映机。源:Nicolas Vega

图:同一个 OLED 面板前方使用磨砂镀膜与镜面镀膜的微观区别。可以看到没有漫反射的镜面更“通透”。当然,后者的纯色光更容易聚集,LED 调整亮度所必须的频闪亮度变化也更大,容易导致眼部刺痛、散光。源:The Display Guy
抖动滤镜(Dither Filter)
源自早期操作系统只能显示有限数量的颜色,因此采用了高频闪烁两种颜色的方法来欺骗视觉(副作用是使人感到晕眩)。在图像、音频和低端显示器中,抖动滤镜代表通过分辨率或采样率来换取位深的加噪补偿手段。
具体来说,通过间隔几个像素就调亮/调暗一个像素的颜色,使得宏观整体上看起来像是淡化或加深;在音频位深分量两端的采样点间成比例的(以方形波或三角波信号)快速摆动,从而利用扬声器反应速度,起到淡化或深化偏移宏观上位深的效果。
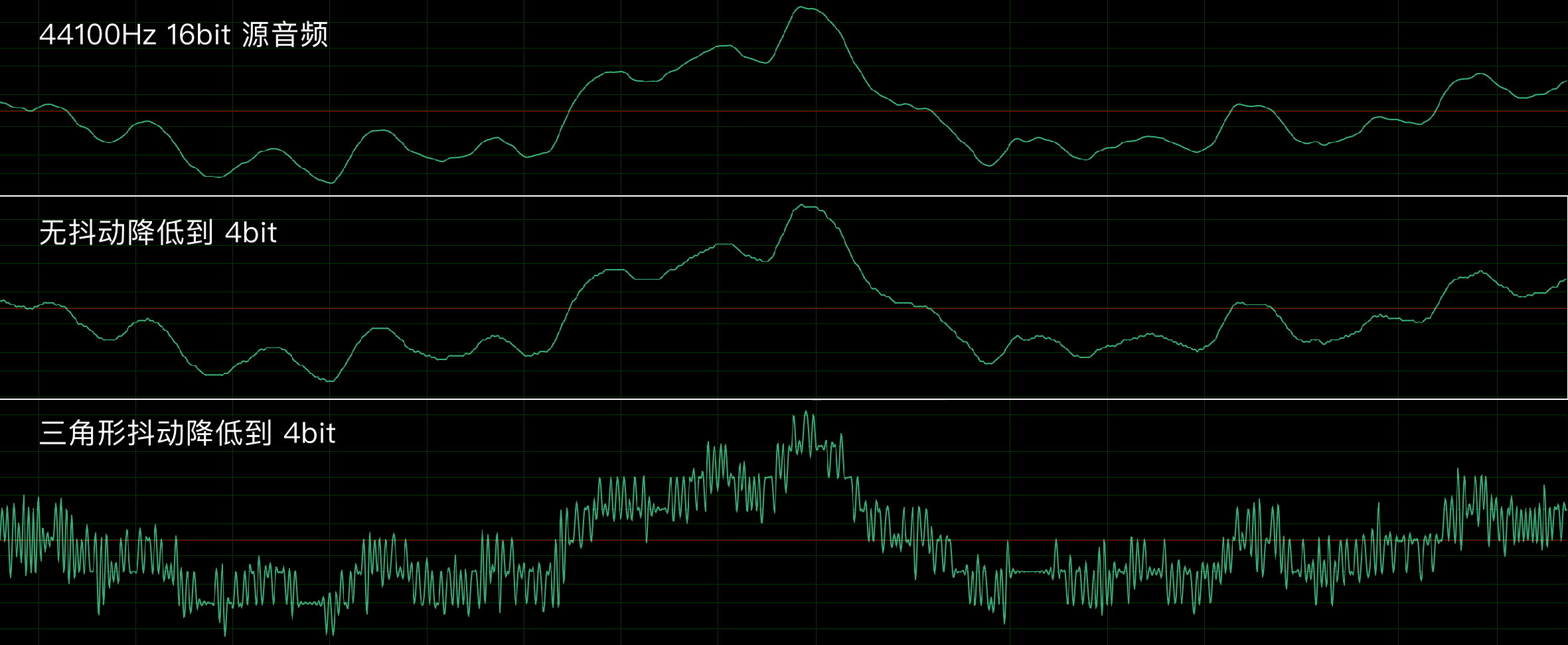

抖动滤镜的效果主要是欺骗视觉,但因为效果独特,所以衍生出了 Ditherpunk 抖动朋克美术。典型如 1bit 游戏《奥博拉丁的回归》贯彻了这种风格——利用随机,蓝噪声,蓝噪声,黄金分割,Riemersma 等不同的加噪算法来定义游戏引擎的材质。
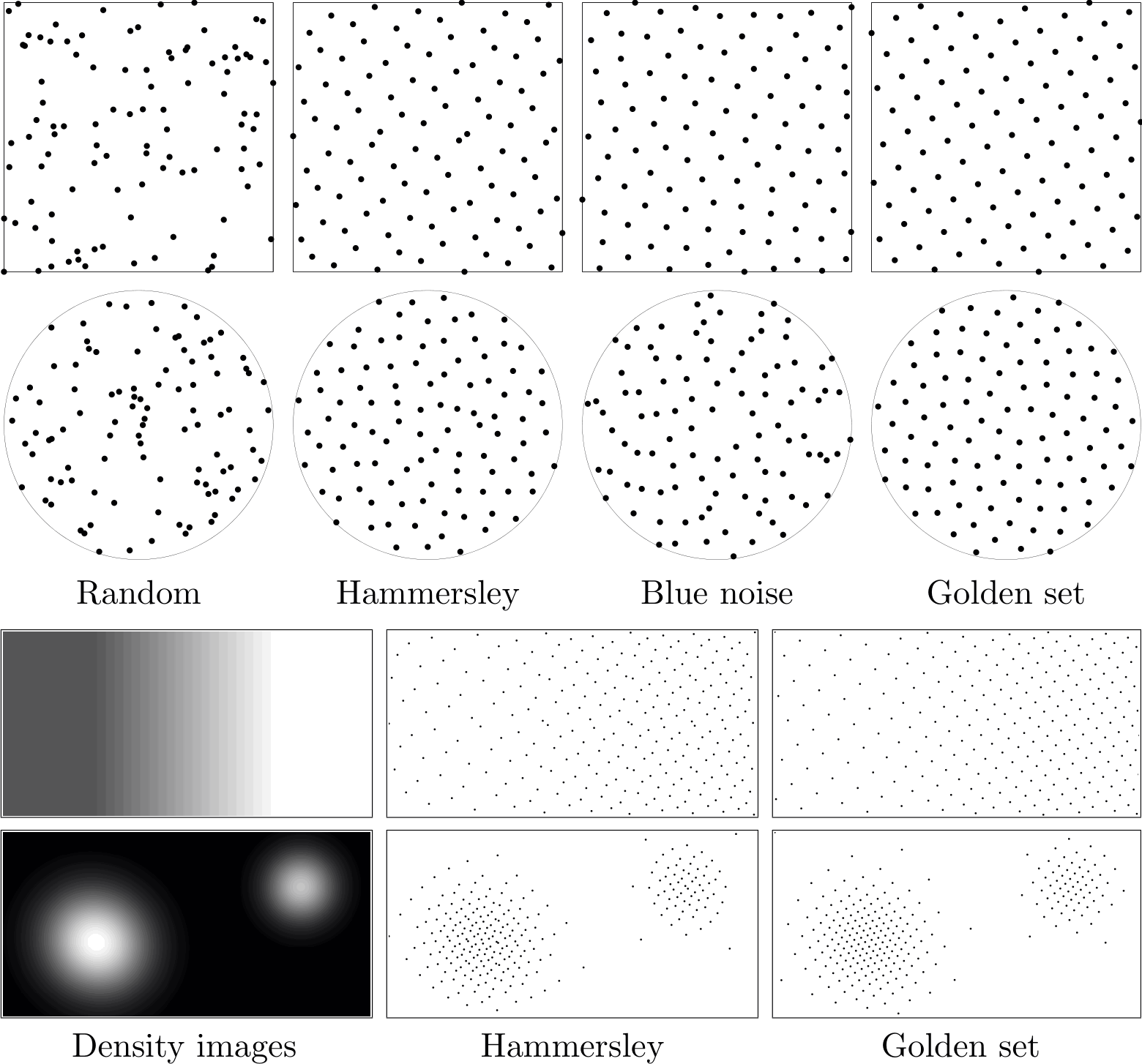
图:图像噪声算法
缩放滤镜(Resize Filter)
Windows 系统一般用双线性缩放放大 PPI 小的软件,视频播放器一般用 bicubic 或 lanczos 插值
临近取样插值 Nearest Neighbour interpolation(NN):
- 2x2 的四个像素点移动到缩放后的四个位置
- 待插值的像素中,距离哪四个点近的像素就取哪个像素的值
双线性插值 Bi-linear interpolation(Bi-lerp / Bilinear):
- 2x2 的四个像素点移动到缩放后的四个位置
- 横向和纵向的点(像素值)间各连一条线
- 采样得到中间的像素,完成四边的插值
- 四边之间接着分为横向与纵向边缘
- 横向和纵向的边(像素值)间各连一条线,共六横六纵
- 所有线段接着采样得到中间的插值像素点,且在横纵线的两种插值之间取平均
样条插值 Spline interpolation(spline):
- “样条”代表软木条,通过铁钉塑形结合木条的应力做出连贯且一致的曲线
- 这种性质可以用多项式准确描述,而图像中的“铁钉”就是像素值
- 图像中的“木条”就是在 n 个“铁钉”构成的 n-1 个区间里各画一条曲线
- 二次多项式插值 quadratic interpolation 代表三个点间用二次多项式插值
- 三次多项式插值 cubic interpolation 代表四个点间用三次多项式插值,适用于放大图像
- 连起的线必须平滑连贯,数学上叫做“二阶导数连续”
- 因此,放大一个 2x2 的区间需要 4x4 范围的采样点
- 插值的与逻辑和双线性插值一致,同时是三次多项式插值,则是双三次多项式插值 bi-cubic interpolation
Lanczos 插值:
使用 sinc 函数取近似,且引入了窗函数来矫正 sinc 函数,同时要计算 lanczos 核实现插值。计算量大,准确度略高于 bicubic 插值。
神经网络缩放滤镜:
通过认知大量训练数据,在其中找出更高维度规律的情况下,利用这些规律推断像素值。计算量极大,准确度时高时低。
宽高比(Aspect Ratio)
矩形的最小两边的比例,被中国航空航天称为展弦比。被忽略的“长”是屏幕相对人眼的 z 轴。而换算长短边如 16:9 高 720 的方形像素视频,其宽就是 \( 720 \div 9 \times 16 = 1280 \)。
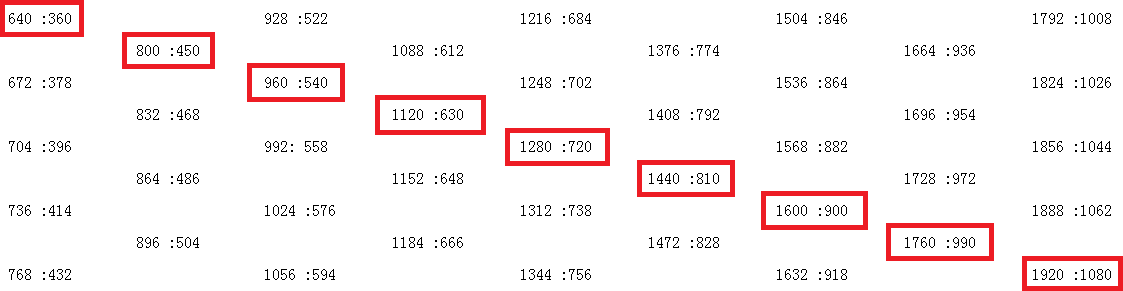
图:16:9 的矩形整数偶数放大后的图像分辨率
图片格式一般支持奇数分辨率,视频一般仅支持偶数分辨率。
程序的交互界面(Interface)
图形界面交互(Graphic user interface、GUI、UI):通过图形元素(如按钮、滑块、菜单等)进行用户交互的界面设计。随着程序复杂度的增加,设计出好用的界面会变得更加困难。因此,只有在利润丰厚、注重美学设计、且拥有设计人才的行业才会推出外观精美的 GUI。然而,好看不等于好用。在视频压制相关的任务中,加了图形界面反而会引出一系列问题,例如关键功能或信息缺失、报错信息丢失、内容溢出窗口、操作流程复杂化等问题。
图:音频插件宿主软件 FL Studio,外加一堆免费和“免费”音频插件随便摆放的外观
图:网页服务器宿主软件 XAMPP 的 GUI(左下为 CLI),作为跨行业对比
命令行交互(Commandline interface、CLI):在如 Terminal、Bash、CMD 和 PowerShell 的终端环境中,用户可以手动输入命令并按回车键查看结果。通常,只要输出结果有一定的文本排版,就可以轻松阅读。随着使用的增加,CLI 可能反而会变得比 GUI 更方便。然而,由于某些命令太长,而且需要储存变量,因此为了简化操作,人们会将其写作批处理、Shell 等命令脚本文件。例如PowerShell 一站式系统硬件检测的脚本。
图:Ubuntu(Linux 系统)的终端命令交互程序窗口。
应用编程交互(Application programming interface、API):定义编译好的软件应用程序之间应该如何相互通信的规则。主要分为跨网络的 API(调用数据库、调用其他网站资源)和本地程序之间(软件、操作系统、电脑硬件)的 API。API 可以被看作是 CLI 的映射。
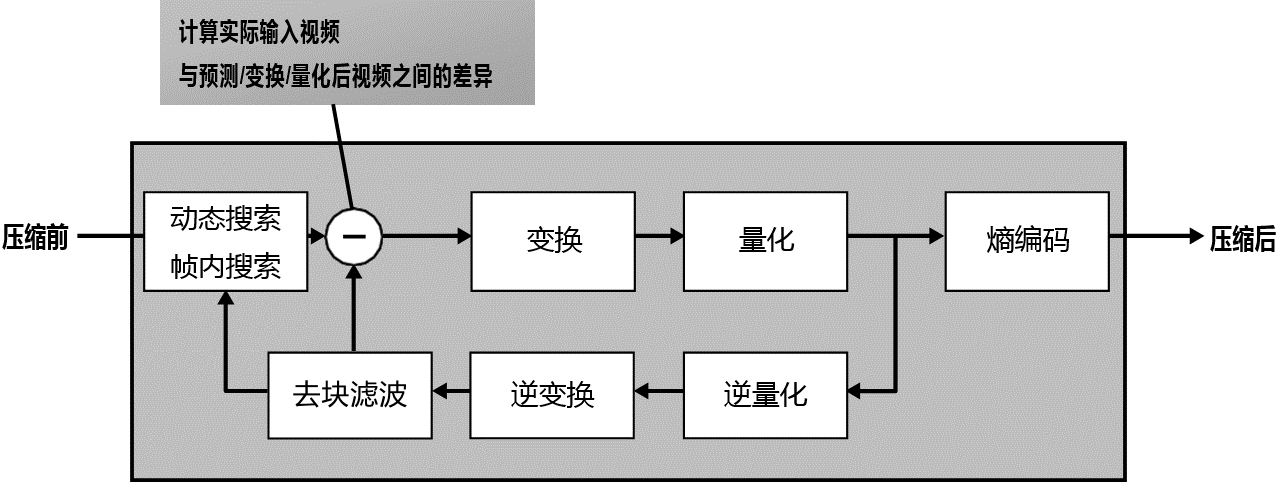
编解码的过程
注:实际情况下会因为软硬件,用户设定,以及操作系统逻辑的不同而变。
视频的打开
- 用户点击打开视频文件
- 操作系统根据文件扩展名,查找默认的应用程序
- 应用程序根据文件路径,在文件系统中定位视频,并读取文件的元数据,包括文件头和其他格式信息
- 应用程序根据文件的元数据确定所需的解码器和其他资源,然后在计算机的内存中分配空间
- 应用程序调用适当的解码器来解析视频文件,并将视频和音频数据解码为未压缩的原始数据
- 解码后的视频数据传递给图形处理芯片 GPU,而音频数据则传递给声音转换芯片 DAC。
- GPU 将图像信号转换为图像,输出到显示器
- 显示器上的芯片将图像数据转换为对每个像素上电路的控制,并显示出来
- DAC 将音频信号转换为模拟信号,并通过扬声器播放出来
视频的压制
- 打开编码器
- 用户可以通过多种方法打开编码器:
- 如果编码器内置了如 Lavf 的解封装和解码动态链接库,则编码器可以自动解封装、解码和封装视频文件:
- GUI 软件通过发送 CLI 命令,或者使用像 Bash/CMD 这样的 CLI 工具来打开编码器程序。
- 编码器通常根据输出文件的后缀名自动封装视频文件。
- 如果编码器没有内置解封装解码功能,则通常会使用 ffmpeg 内部的解封装工具和编码器。
- 可以使用 pipe 将上游如 ffmpeg、VapourSynth、avs2yuv 连接到下游如 x264/5 的编码器
- 如果编码器内置了如 Lavf 的解封装和解码动态链接库,则编码器可以自动解封装、解码和封装视频文件:
- 用户可以通过多种方法打开编码器:
- 解封装和解码
- 解封装解码工具将已解压缩的 YUV for MPEG 或 RAW 格式视频流传递给编码器,编码器得到输入信号。
- 如果输入是 RGB24 的 RAW 色彩空间视频流,通常需要使用编码器内置的色彩空间转换功能将其转换为 YUV 格式。
- 如果编码器是录像设备的一部分,则需要根据录像设置将视频流拆分为视频帧。
- 解封装解码工具将已解压缩的 YUV for MPEG 或 RAW 格式视频流传递给编码器,编码器得到输入信号。
- 编码过程
- 前瞻进程(Lookahead):预先分析未来几帧的复杂度、运动和场景切换 scenecut 的估计、I-P-B 帧类型决策
- 帧类型决策由最短路径算法(Shortest Path)确立
- 粗分块:虚拟步骤,编解码器直接根据指定可用的大小开始在特定位置上操作,因此搜索等操作默认这步已经完成
- x264:宏块 Macroblock MB(16x16)
- x265:编码树单元 Coding Tree Unit CTU(最大 64x64、最小 32x32)
- AV1:特大块 Superblock(最大 128x128,但为了兼容现有硬编硬解、所以很多步骤上等效于 64x64)
- 动态搜索:Motion Estimation(ME)找到当前帧与参考帧之间的相似区域,并为每个块分配动态向量。
- 动态补偿:Motion Compensation(MC)对比实际画面与搜索到的向量生成预测块,并补偿¼子像素精度的对齐偏差。
- 细分块:根据 MEMC,进一步细分宏块或编码树单元到最小的 4x4 编码块上。
- 帧间残差编码:对比实际画面与动态搜索与补偿后所得的图像,得到残差,并对残差进行变换和量化,存储到 P-B 帧上,在解码时与 I 帧叠加以得到原始画面。
- 帧内预测:在帧内编码块上检查候选出冗余最好的帧内编码方法(夹角、DC、趋平、无),选中方法后得到帧内预测后的块,即预测块。
- 开启率失真优化则进一步检查画质同码率下画质是否也最好
- 帧内残差编码:对比实际画面与帧内预测得到的残差块,进行变换和量化,存储在预测块中,在解码时与预测模式叠加以得到原始画面。
- 跳过块编码:跳过帧间或帧内残差编码的块,进行变换和量化。
- 变换:将图像从空间域转换到低频到高频信号分量之间的每个级别,也称为频域。
- 量化:根据用户设置的质量级别,削减高频信号分量,这一步骤对画质和文件大小影响最大。
- 熵编码/文本编码:将变换和量化后的频域分量统计为最小可能的二进制数。
- 前瞻进程(Lookahead):预先分析未来几帧的复杂度、运动和场景切换 scenecut 的估计、I-P-B 帧类型决策
- 生成视频流
- 编码器将生成的数据流逐个 GOP Group of Pictures 打包为文件,得到完整视频流文件
- 如有必要,附加如色彩空间、Supplemental Enhancement Information SEI、VUI、HDR 等元数据
- 封装视频流
- 用户可以通过多种方法将视频流封装为 .mp4、.mkv、.mov 等格式:
- 如果编码器内置了像 Lavf 的解封装解码动态链接库,编码器可以根据输出命令行的文件后缀名自动完成。
- 如果编码器没有内置解封装解码功能,则通常会使用 ffmpeg 内部的编码器和解封装工具,使编码完成后自动封装。
- 可以使用工具如 ffmpeg、MP4Box,MKVToolNix 等来进行封装。
- 封装文件使得播放器的程序逻辑变得简单(例如,在读取视频流之前就获取视音频格式,而不是先打开所有解码器,再关掉不兼容的解码器)
- 如有必要,附加音频流/音轨、字幕轨、字体等文件(但要根据封装文件的兼容性判断)
- 用户可以通过多种方法将视频流封装为 .mp4、.mkv、.mov 等格式:
视频编码的标准(MDN Docs)
Encoding Standard 一般称为 Codec。
| ♙编码 | 全称 | 一般封装格式 |
|---|---|---|
| AV1 | AOMedia Video 1 | MP4,WebM,MKV |
| AVC (H.264) | Advanced Video Coding | 3GP,MP4 |
| H.263 | H.263 Video | 3GP |
| HEVC (H.265) | High Efficiency Video Coding | MP4 |
| MP4V-ES | MPEG-4 Video Elemental Stream | 3GP,MP4 |
| MPEG-1 | MPEG-1 Part 2 Visual | MPEG,QuickTime |
| MPEG-2 | MPEG-2 Part 2 Visual | MP4,MPEG,QuickTime |
| Theora | Theora | Ogg |
| VP8 | Video Processor 8 | 3GP,Ogg,WebM |
| VP9 | Video Processor 9 | MP4,Ogg,WebM |
其中,“H.264”的 H 代表国际电信联盟——电信标准化部门(ITU‑T)中的 H 系列建议指南,例如 ITU-T H.810 个人健康系统(血压计、血糖仪、体重秤)的交互设计建议指南。一些符合某个 H 系列视频编码建议指南的视频编码器会将这个标号写在程序名字上,就有了所谓的 x264,x265。
命令行参数
由开发者定义的键—值(key—value)数据,使得用户能够给代码函数或程序中的一些变量赋值,从而调整程序的运行逻辑。命令一般由空格作为分隔符,但为了给程序内的程序传递命令就会出现会分隔符混淆,因此这些内部程序会定义一套不同的分隔符规则,例如 ffmpeg 调用内部库 API 的 "命令=值:命令=值" 写法。
例如,x264 使用 CLI 参数的例子:
x264.exe --rc-lookahead 90 --bframes 12 --b-adapt 2 --me umh --subme 9 --merange 48 --no-fast-pskip --direct auto --weightb --keyint 360 --min-keyint 5 --ref 3 --crf 20 --qpmin 9 --chroma-qp-offset -2 --aq-mode 3 --aq-strength 0.7 --trellis 2 --deblock 0:0 --psy-rd 0.77:0.22 --fgo 10 --nr 4 --output ".\输出.mp4" ".\导入.mp4"
以及 ffmpeg 中使用 CLI 参数启用 libx264,通过 -x264-params 发送 API 参数的例子:
ffmpeg.exe -loglevel 16 -hwaccel auto -y -hide_banner -i ".\导入.mp4" -c:v libx264 -x264-params "rc-lookahead=90:bframes=12:b-adapt=2:me=umh:subme=9:merange=48:fast-pskip=0:direct=auto:weightb=1:keyint=360:min-keyint=5:ref=3:crf=20:qpmin=9:chroma-qp-offset=-2:aq-mode=3:aq-strength=0.7:trellis=2:deblock=0,0:psy-rd=0.77,0.22:nr=4" -fps_mode passthrough -c:a copy ".\输出.mp4"
ffmpeg 中,导入文件由 -i 参数完成,因为 ffmpeg 支持导入多个文件,而每个文件后跟随一些处理命令就需要较为严格的命令添加顺序,而 x264/5 这些编码器一般只是导入一个文件,所以在末尾加一个路径到文件的字符串就代表导入文件了。

图:使用命令行窗口启动视频压制命令后,视频编码器会给出大致这些信息
本教程中命令行参数的说明格式
--参数
<开关 | 整数 A~B | 浮点 A~B | 其它格式,默认值,限制>说明信息,特点注解,推荐这个值,其它情况可设这个值。
- 情况 1:特点如此,推荐这个值
- 情况 2:特点如此,推荐这个值
管道(Pipe)
一种在进程/软件之间通信的操作系统机制。在命令行中写作通过链接符 | 串联起来是两段命令,而两段命令间的数据一般由默认输出 standard output(stdout)和默认输入 standard input(stdin)实现,因此不需要手动添加输出和输入命令。报错则为 stderr。在涉及到文件输入输出的程序时则需要手动指定“-”符号到程序的输入命令中,以取代文件的输入。
串流管道 Stream-based pipe
Windows CMD、Linux Bash 的管道模式,用于传输纯数据,其中的程序同步运行,持续地传输上游输出到下游。适用于串流作业和处理流数据,包括视音频和文本流。
串流管道详解
Linux Bash 中使用 for txt in *.txt; do md5sum $txt; done | awk '{print $2, $1}' | sort -bn 代表:
- 在当前命令行目录下遍历 .txt 文件,生成多行“哈希值 文件名”字符串
- 将文本流传给排列功能,将每行字符的顺序改为“文件名 哈希值”
- 将文本流传给排序功能,按照文件名的数字重排行号并忽略空格,得到按顺序排版的“文件名 哈希值”
对象管道(Object-based pipe)
PowerShell 的管道模式,用于传输结构化的对象(变量本身),而不是纯数据。其中的程序按顺序接力,一个程序/协议/函数跑完后再打开下一个。适用于处理对象化数据(面向对象的应用),所以不适合用于处理视音频流文件。
指定默认输入和报错
J:\ffmpeg.exe -i D:\文件夹\源.mp4 -an -f yuv4mpegpipe - | J:\x264-r3206.exe --y4m - --output D:\文件夹\测试.h264 2> D:\文件夹\报错.txt
以上命令代表在 Windows CMD 中:
- ffmpeg 导入 "D:\文件夹" 下的一个视频文件
- ffmpeg 使用
-an命令指定关闭音频编码 - ffmpeg 使用
-f命令指定使用 YUV For MPEG 管道格式,相对于 rawpipe 格式提供了一些视频元数据,使 x264 了解视频的分辨率、帧率、位深等基本参数,否则需在命令行中手动指定 - ffmpeg 使用“-"替代文件路径,指定导出文件到管道
- x264 使用
--y4m -命令指定使用 YUV For MPEG 管道格式,并设定输入流为“-” - x264 导出压制出、未封装的视频流到
D:\文件夹下 - x264 导出任何可能的报错信息到
D:\文件夹下,以避免管道上游的信息覆盖或埋藏
管道的问题与上位替代
- 管道下游程序的报错常被管道上游覆盖或埋藏,需要额外指定报错信息导出路径
- 虽有编程爱好者集成 LAVF 编解码到 x264 编码器中(封装、解封装视频流功能),但不是所有视频编码器都受到这种待遇
- 视频流已经占据了管道,音频流的封装就需要等第二行命令实现了
- 同理,若视频编码命令出错,那么自动化脚本中的封装命令也会失败,使得原本的报错信息更难找到
而上面的命令可以被简化到直接调用 ffmpeg 内置的 libx264 库,从而用一条命令实现压制与封装:
J:\ffmpeg.exe -i D:\文件夹\源.mp4 -c:v libx264 -fps_mode passthrough -c:a copy D:\文件夹\输出.mp4
这种命令行环境下,要注意音频流与封装格式的兼容性。如果要替换或添加新音频轨道,则在 ffmpeg 命令行中输入音频流,并通过 -map、-c 命令指定替换或添加。
数据结构
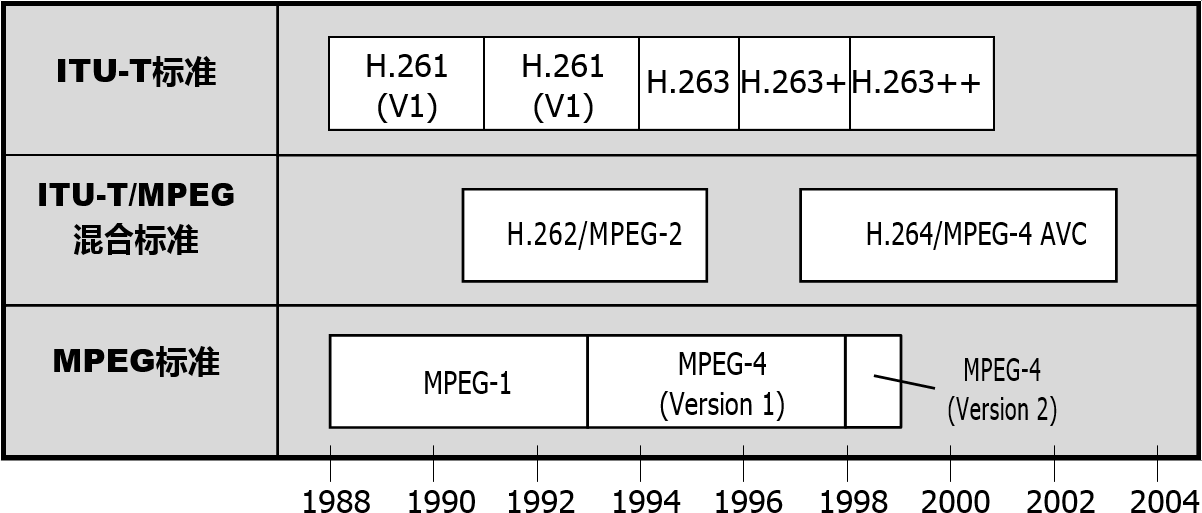
帧的结构
在 Advanced Video Coding AVC 中,帧的下级结构按照分辨率大小分为条带组 → 条带 → 宏块 → 块 / Slice group → Slice → Macroblock → Block。从大小和功能上细分为:
- 帧(Frame):
- 关键帧:I/i 帧
- 参考帧:P 帧、B/b 帧
- 条带组(Slice group):
- 由灵活宏块排序 Flexible Macroblock Ordering FMO 划分
- 优化解码延迟,提高压缩和参考错误恢复能力
- 条带(Slice):
- 关键帧下:I/i 条带
- 参考帧下:I/i 条带、P 条带、B/b 条带
- 空条带:填充网络数据包中,数据不足而无法填满的空位
- 冗余条带:提高数据抗丢包,抗损坏的能力
- 宏块(Macroblock):
- 粗分块,在动态搜索与补偿前完成,面积为 16x16 像素
- 块(Block):
- 细分块,在动态搜索与补偿后完成,面积为 8x8 或 4x4 像素
- 关键帧下:帧内预测块、帧间预测块
- 参考帧下:帧内预测块、帧间预测块、帧内残差块、帧间残差块
- 帧间预测块:将 I 块叠加帧间动态矢量后变出的帧间预测画面
- 帧内预测块:从块左侧和顶部的一排相邻像素上,叠加插值算法变出的帧内预测画面
- 残差块:保存帧间和帧内预测无法还原的信息,与预测宏块叠加用。画面复杂则“残差才是本体”
GOP 结构
而相对的,在帧之上的结构被称为图组 Group of pictures。每个 GOP 的创建取决于关键帧间隔设置以及转场判断,其中都包含了 IDR 帧,i 帧,P 帧,Pyramid-B 帧以及 b 帧。一个视频中最少由一个 GOP 组成,同视频长度下 GOP 的数量越多则视频体积越大,解码难度越低。
- 关键帧 IDR 帧,I 帧:
- I 帧 Intra-coded frame独立编码,不依赖于其他帧的关键帧。也可以作为解码的起始点,只是不会刷新参考帧列表,所以强行播放可能会有一些画面错误
- “关键”代表“起到独立解码,随机访问点 Access point,传输错误后重新同步视频流,集中参考源以提高压缩率等关键作用”
- 即时解码刷新 Instantaneous Decoder Refresh 帧是一种带有刷新标记的特殊 I 帧,解码器播放到 IDR 帧时会刷新参考帧列表,因此 IDR 帧之前的帧不再作为参考源,从而隔离了 GOP。
- IDR 帧一般位于 GOP(Group of Pictures)之首。用户拖动进度条时,解码器会寻找最近的 IDR 帧解码
- IDR 帧与 I 帧同为关键帧,有时会被写作 I 帧与 i 帧
- IDR 帧数量过少时,可能会导致以下问题:
- 随机访问会导致参考错误 + 长时间无法纠正画面错误:P,B,b 帧会尝试参考 i 帧之前的帧
- 剪辑困难:专业视频编辑软件会在剪辑视频时会插入新的 IDR 帧以保证预览流畅和准确
- 随机访问困难,因为 GOP 的基础结构不存在,拖动进度条需要从视频开头解码到新的位置以后才能播放
- 拖动进度条代表需要从很远的 IDR 帧(无 IDR 帧则从视频开头)解码到新的位置再继续,等待的时间变得漫长,播放设备的发热增加
- 如果播放器关闭了拖动进度条的精确索引,则拖动进度条会导致进度条位置偏移到其之前很远的 IDR 帧上,或返回开头
- 如果 I 帧数量过少,则会有一串含有 I 条带的 P 帧替代它
- IDR 帧的数量由 Keyframe interval
--keyint参数和--scenecut参数决定 - I 帧的数量由
--min-keyint参数决定
- I 帧 Intra-coded frame独立编码,不依赖于其他帧的关键帧。也可以作为解码的起始点,只是不会刷新参考帧列表,所以强行播放可能会有一些画面错误
- 参考帧 P/B/b 帧:
- 参考帧 P 帧 Prediction frame 含有 I 条带与 P 条带,全部条带都可以给临近的 P,B 帧参考
- 双向参考帧 Bi-directional prediction frame,b 帧含有 i,P,B 条带,只有 i 条带可以给临近的 P,B 帧参考
- 尖塔 B 帧 Pyramid bi-directional prediction frame 含有 I,P,B 条带,全部条带都可以给临近的 P,B 帧参考
多参考帧的结构
x264 首次引入了超过前后一帧长度的帧间参考范围。因此动态搜索也能更好的检查运动向量的时间一致性,从而减少动态噪点对动态搜索的干扰,同时提高了压缩。多参考帧不是越长越好,而是只要满足「一帧只要参考前后各 N 帧的信息就足以还原自身」的长度就是最优解的,而超过后会导致视频体积增加,同时画质降低。这个长度一般是前后各 3 帧,即 --ref 3。
前瞻进程 Lookahead
最先启动,设立关键帧和参考帧,决定了 GOP 划分、帧类型推演、转场设立、逐帧量化强度等多项初始数据。
视频编码的前瞻进程涉及多个复杂步骤,因此并无直观的图解;不过尽管原理不同,前瞻型纯追踪算法 Pure pursuit lookahead 有着一致的“让程序变聪明”概念,并解释了前瞻进程长度对精度的影响:
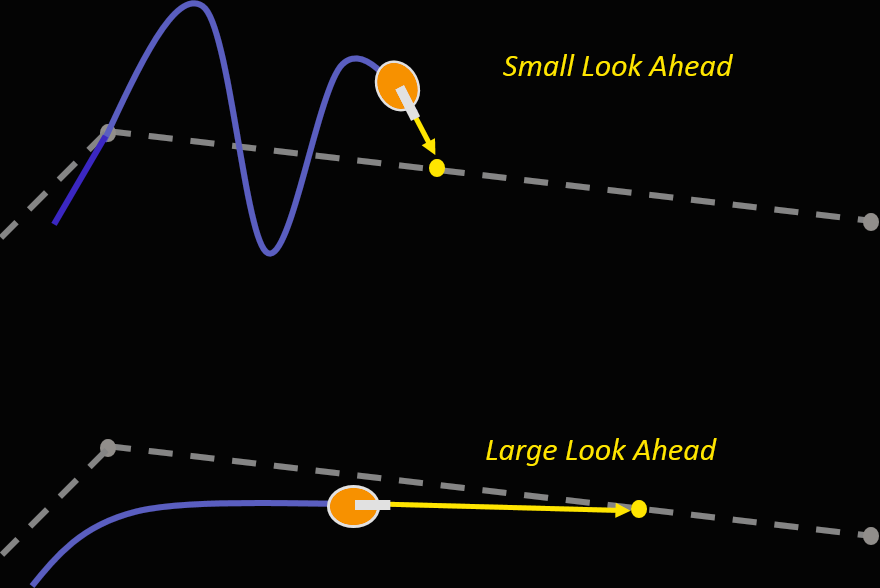
图:前瞻型纯追踪算法 Pure pursuit lookahead。见MatLab
前瞻进程距离短时,计算容易出现过冲(Overshoot)现象;距离长则虽然判断稳定,但程序占用的缓存更多,延迟也往往更大。
--keyint
<整数,默认 250,推荐 9~12 倍帧率(即 9~12 秒)>指定最长关键帧间隔(GOP 长度)。当距离上一个 IDR 帧达到阈值时,覆盖帧类型推演而直接设立 IDR 帧,开始一个新 GOP,并弃用 IDR 帧前的所有数据。
- 如果视频用于多轨剪辑素材(且频繁拖动进度条),则建议 6~8 倍帧率(即 6~8 秒)以降低解码器负载,提高流畅度
--min-keyint
<整数,默认 25>指定最小关键帧(IDR 帧)间隔。当转场判断(scenecut)被触发时,这个间隔之内的设立为 I 帧,之外的设立为 IDR 帧。非关键帧的 I 帧虽然也是独立图像,但不刷新解码器缓冲区,因此帧间参考会继续。有两种设定逻辑,而它们给出的画质都一样,区别在于体积:
- keyint÷2 ~ keyint:设立新 I 帧意味着一批帧内编码任务被设立,而设立 IDR 帧还要重新开始帧间编码,不急着设立 IDR 帧虽然对压缩/画质不好,但也不容易在录制时卡顿
- 1:一帧被判为 I 帧,而不是 P、B 帧,已经说明了说明前后并不适合参考。因此即使两帧挨得很近,也有可能是两个不同的场景,于是设立 IDR 帧拆分成 GOP 是画质最好,但帧间参考最差的选项。
- 5~10:相比 1 在 24~60 fps 帧率下略微放宽要求(约 0.1~.15 秒),避免画面闪烁、闪回插入镜头(如意识流蒙太奇剪辑)时 IDR 帧数暴涨,维持帧间参考;推荐搭配
--gop-lookahead使用
--ref
<整数 1~16>多参考帧前后帧数半径,一图流设 1。必须要在溯全尽可能多块的情况下降低参考长度,所以推荐 3:
--no-mixed-refs
<开关>关闭参考帧混合溯块(16×8,8×8 分块的参考)以提速,增加误参考。不推荐
--scenecut
<整数,不推荐用>Lookahead 中两帧差距达到该参数值则触发转场
--seek
<整数,默认 0>从第几帧开始压缩
--frames
<整数,默认全部>一共压缩多少帧
--fps
<整数或除法,自动开启 --force-cfr>设定输出视频帧率,除非有指定的必要(如源视频为 RAW YUV 或帧率错误),否则无需配置。
--force-cfr
<开关>强制设定视频帧到整数时间码,可能用于对齐小数帧率的误差(如 23.976 或 24000/1001 变成 23.977)用
--fullrange
<开关,默认关>启用 0~255 色彩范围,而不是默认的 16~235。应保持和源一致
动态预测(Motion Prediction、MP)
视频往往会出现“占据一定画面的物件朝向一处平移”的情况,在视频帧中表现为“某个区域的分块拥有高度相似的运动向量”。这些重复性的动态向量分布规律肉眼可见,但动态搜索算法只会一味的盲找,因此我们提前给动态搜索一个搜索起点,就可以降本增效了。
实际上,动态预测得到的向量往往相当靠谱,因此编码器会以“预测动态向量(PMV)+ 动态向量差(MVD)”的形式记录每个帧间块的动态信息,再冗余掉相同的预测动态向量,从而进一步提高压缩。纵然一支动态向量的信息不多,但放眼到整个视频的所有帧间参考时,质变也就产生了。
x264 使用了 --direct 指定预测方法(时间法/空间法/两者都用)。x265 则使用了更高级的 AMVP + Merge 预测算法。
--direct
<temporal/spatial/auto> 指定动态搜索判断方式的参数,除直播和低性能设备录屏外建议 auto
动态搜索(Motion Estimation、ME)

图:Elephants Dream 视频素材某帧的动态向量分布。来源:维基百科
注:它的专业术语是运动搜索、运动估计;具体到视频编码时,要加上“整数像素”的前缀。
在连续帧间画面中,进行运动估计的整数像素精度动态信息搜索步骤,涵盖了各式搜索算法与各样的信号处理用途。具体步骤是以被参考帧内的已编码块(Coded Block)为起点,尝试通过位移来匹配相邻帧的画面,从而找到一个失真最小的向量(Direction of minimal distortion、DMD),这个向量就是整数动态向量。
为了找到可用的最小失真朝向,并且避免进行算力占用巨大的全搜索(Exhaustive Search),动态搜索演化出了多种匹配的图案和算法。其中,较为聪明的动态搜索算法是多级算法,它们首会先尝试在较大范围进行粗略搜索,再以大致最佳区域为中心进行精细搜索,从而(包括在噪点干扰下)多快好省地找到整数动态向量。在整数动态搜索之后,还会由子像素动态搜索(Sub-pel Motion Estimation)来进一步做对齐,最终,这个动态向量被用于冗余预测块,以及对高动态画面提高有损压缩强度,从而压缩体积并优化码率的分配。
如果动态搜索的过程有缺失或不够理想,参考帧与分块的建立会变得低效,码率分配也会变得不够合理,导致画质的降低和码率的增加。
注:动态搜索的用途包括计算机视觉的目标跟踪(自动驾驶、监控与制导系统)、基于动态向量的分辨率超采样(如 DLSS)、视频驱动的 3D 建模与插帧、剪辑后期的视频去抖(如 Adobe Premiere 的变形稳定器效果)、智能电视内置的动态画质增强(虽然大多情况下效果一般)等等。

图:宏块上帧间的动态向量
简化模型下,动态搜索得到帧间向量表,帧间向量表加上上帧的画面得到预测帧,原始帧减去预测帧得到残差帧,残差帧储存为参考帧,得到帧间结构。x264 使用了不对称多六边形搜索 Uneven multiple Hexagon,从而让一个搜索算法在多个分辨率下检查画面,制衡了动态噪点对传统动态搜索算法的干扰。搜索算法详见 x265 教程。
--me
<dia/hex/umh/esa/tesa,推荐 umh>动态搜索算法,最终目的是找到准确的动态信息走向。dia、hex 适合 --merange 16 或更小的范围,一般用于直播与录屏(降低编码延迟);umh 适合 --merange 32 及更大搜索直径。此外就是几乎没有用的 esa、tesa 全搜索/穷举法了,其中 esa 是优化过的 tesa。
--merange
<整数,推荐 4 的倍数,需 me>完全取决于 ME 算法和分辨率,过大会因「找不到更好,找到也是错」而损失画质和压缩。
- 1920x1080 下推荐48左右
- 3840x2160 下推荐52左右
- me hex 下设16
- me umh 设≥32
--no-fast-pskip
<开关,推荐开> 关闭跳过编码 P 帧的功能
--no-chroma-me
<开关,推荐直播/录屏用> 跳过色度平面动态搜索,将亮度平面直接应用。可能对画质有略微负面影响
绝对变换差和 SATD
Sum of absolute transformed difference 为两个变换块间做差,取和,取绝对值的步骤:
- 首先计算两个块 B 的插值,记做残差块 D:\(\text{D}(x,y) = B(x,y) - B\prime(x,y)\)
- 然后通过哈达码变换(相比 DCT 节约算力),得到变换残差块:\(T(D)\)
- 省略这一步,则算法叫做绝对差(Sum of absolute difference、SAD)
- 最后,变换残差块的每个像素取绝对值和:\(\text{SATD}(B,B\prime) = \sum_{x=0}^{n-1}{\sum_{y=0}^{n-1}}| T(D(x,y)) |\)
注:为了简化所以写作 \(T(D(x,y))\),实际这样相当于每加一个像素值就要变换一遍
动态补偿/运动补偿(Motion Compensation、MC)
整数像素动态搜索虽看起来很准,但精度终归有限,只能算是“粗加工预测”;直接使用整数动态向量会导致纹理细节和物件边缘信息的丢失。为此,编码器需要对向量“精加工”——对齐到插值出的 half-pixel(hpel)/ ½ 像素,以及 quarter-pixel(qpel)/ ¼ 像素,使预测画面(指 PU、PB)的残差变小,与输入源画面更一致。
注:虽然看起来只有一个子像素补偿,但这不妨碍动态补偿作为一个完整独立的步骤存在。此外,在 AV1 标准中,动态补偿就不只有一种了。
整数像素动态补偿
视频编码中同动态搜索(ME)。
子像素动态补偿(Subpixel Motion Compensation)
- 线性插值参考帧(有限冲击响应滤镜 FIR),分别生成上采样/放大 2x 和 4x 的副本
- 以整数向量落点为起点搜索放大副本的位置,从而找出率失真代价最小的子像素动态向量位置:
- (J)oule:率失真代价(RD Cost),失真最小的候选最精确
- (D)istortion:使用当前子像素动态向量编码预测块与输入源画面的差异(SATD)
- (R)ate:计算编码这些新向量所产生的码率
- λ:拉格朗日代价
注:率失真优化计算见下方版块的说明。
图:根据动态搜索与补偿所得,完成宏块到块的细分
| 编码器(官方) | 平面——块类型 | 范围精度 | 插值方法 |
|---|---|---|---|
| x264 | 亮度 Y | ½ 像素(hpel) | 6 tap FIR |
| x264 | 亮度 Y | ¼ 像素(qpel) | 双线性插值(Bi-lerp) |
| x264 | 色度 C | hpel+qpel | 上下左右加权平均 |
| x265 | 亮度 Y | hpel+qpel | 上下左右加权平均 |
| x265 | 亮度 Y | ¼像素(qpel) | 两种 7tap FIR |
| x265 | 色度 C | hpel+qpel | 4tap FIR |
表:x264/5 的 hpel~qpel FIR 插值放大算法使用。x264 使用 6tap FIR 滤镜,x265 使用 8tap、7tap 和 4tap FIR 滤镜。

--subme
<整数 1~10,推荐 6~10>调整具体的动态补偿强度,x264 中同时决定模式决策和率失真优化的强度。根据画质和编码速度选择合适的大小:
- 1 逐块 1/4 像素使用 SAD 算法检验一种对齐
- 2 逐块 1/4 像素 SATD 算法检验两种对齐
- 3 逐宏块 1/2 像素 SATD 一次,逐块 1/4 像素 SATD 一次
- 4 逐宏块 1/4 像素 SATD 一次,逐块 1/4 像素 SATD 一次
- 5 同时增加双向参考 B 块
- 6 同时 I,P 帧启用率失真优化处理
- 7 同时 I,P,B,b 帧启用率失真优化处理
- 8 同时 I,P 帧启用
rd-refine功能 - 9 同时 I,P,B,b 帧启用
rd-refine功能 - 10 使用
--me hex动态搜索检验对齐,需--trellis 2 --aq-strength > 0 - 11 关闭所有提前退出,边际效应过大,不推荐使用
rd-refine(内部参数)
<嵌入 --subme 8 中,x265 中可手动打开> 率失真优化分析帧内预测的最佳量化和分块结果,耗时换压缩率和画质。x264 中还包括了最优动态向量的分析
细分块
--partitions
<字符串 p8x8,p4x4,b8x8,i8x8,i4x4/none/all,默认 p8x8,b8x8,i8x8,i4x4,推荐 all>允许的细分块种类。增加分块种类会增加计算负载,但对现在的 6~16 核消费级 CPU 来说无咎。因此推荐 all
- 开启 p8x8 会同时启用 p16x8,p8x16
- 开启 p4x4 会同时启用 p8x4,p4x8
- 开启 b8x8 会同时启用 b16x8,b8x16
- 因为 边际效益太小,x264 开发者取消了 b4x4 分块
变换
模拟信号转换为数字信号的主要步骤之一——将音量、亮度、温度、压力等信号/信息抽离为单一结构的复杂组成状态,如果这个单一结构是某种波形,那么就是不同振幅、频率和相位(即该波形的各种形态)的复杂组成:
- 振幅:波峰到波谷的高度距离,越大则声音越响,图像明暗处差距越大
- 频率:单位时间下的波周期次数(如演奏家按下琴键的次数每秒),越高则能表示的音高越高,图像越锐利
- 相位:波形在时间/空间的位置,决定了与其它波形的叠加和干涉程度
“DCT 像素”一般被称为系子(coefficients、即分量、或有相关值)。这些系子的强度可以为负数(波形反相)或者小数(微调波形,因计算机算整数更快且无需考虑舍入错误而少见)。变换块左上角的系数是直流(DC、Direct current)分量,代表整体亮度水平,其余的系数是交流(AC、Alternate current)分量,表示图像中的细节和纹理信息。
注:变换处理使得信号得以被翻译解构,例如可以将音频转换为 MIDI 键位,再整理出纯钢琴的“Vocaloid”音乐:Soundcloud / AcFun / 哔哩哔哩。
量化
根据压缩强度给出一个除数或矩阵数组,将变换结果的每个值除以这个除数或矩阵中同位的值,只保留和使用商来解码播放,从而实现压缩。这步操作是压缩中画面损失最大的步骤。
量化值(Quantization Parameter、QP)
由 CRF,ABR 等码率质量控制模式算出,以及率失真优化量化、模式决策等步骤所调整的中间变量
量化步长 \(Q_{\text{step}}\)
Quantization Step-size 是量化值量化强度参数值与实际量化强度之间的映射值。规则大致是量化强度增加 1,则 qStep 增加 0.125;QP 每 +6 则 qStep 乘以 2,使其越往后增量越大:
| QP | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 12 | 14 | 16 | 18 | 20 | 22 | 24 | 26 | 28 | 30 | 32 | 34 | 36 | 38 | 40… |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| \(Q_{\text{step}}\) | 0.625 | 0.6875 | 0.8125 | 0.875 | 1 | 1.125 | 1.25 | 1.375 | 1.625 | 1.75 | 2 | 2.5 | 3.25 | 4 | 5 | 6.5 | 8 | 10 | 13 | 16 | 20 | 26 | 32 | 40 | 52 | 64… |
x264 中,量化值大致上存在于以下几处:
| 步骤 | 名称 | 应用 |
|---|---|---|
| 率控制 | CRF/ABR | 逐帧量化强度(或全局量化强度) |
| I-P 帧质量比 | I-P Ratio | P 帧量化强度 |
| P-B 帧质量比 | P-B Ratio | B 帧量化强度 |
| 自适应量化 | Adaptive Quantization (AQ) | 逐块量化强度 |
| (率失真优化)模式决策 | Mode Decision MD | 逐块量化强度 |
| 率失真优化量化 | Rate-distortion optimized quantization RDOQ | 逐块量化强度 |
| 色度块量化强度偏移 | --chroma-qp-offset |
亮度与色度块量化强度 |
率控制
有损压缩中,码率分配本身会决定压缩视频的画质。这是因为参考帧 P、B 帧自身的主要信息来自于被参考帧 I 帧,其中被冗余的宏块只储存“相对于被参考帧的动态向量”,和“残差画面”。这种画面并不锐利,因而(在熵编码后的)体积占比非常小。而尽管被参考帧 I 帧的体积很大,但 I 帧自身的画面为其后的若干至数百帧提供了参考,使得高画质的 I 帧反而提高了帧间冗余压缩率(与使用 10bit 位深后,码率不增反降的原因相同)。假如被参考帧 I 帧的有损压缩较高,那么在环路滤镜组/率失真优化过程中,编码器会发现 I 帧与 P、B 帧之间不太相像;便会提高残差画面的信息量。于是虽然峰值码率会降低,但 I 帧后的一系列帧都会比以往大一些,造成整体的码率/文件体积上升。在这个基础上:
- 如果视频本身的画面变化偏大,那么参考帧 P、B 帧一开始就会储存更多的残差信息
- 如果一开始就要求限制峰值码率,那么即使文件体积增加,码率提高也是没办法的事
- 如果一开始就要求固定文件体积大小(不超过某个程度),那么原本的“码率提高”就会完全变成“画质降低”
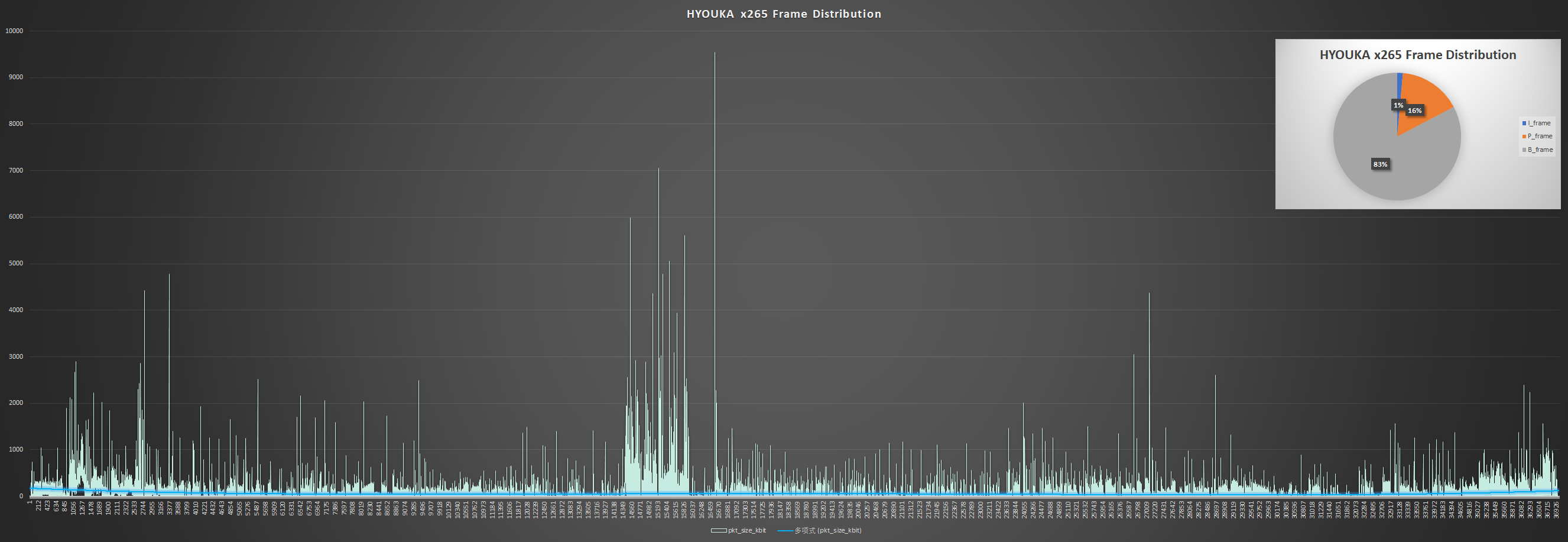
图:这段 1920x1080 视频约有 36000 帧,其中 I 帧占 1%。从趋势线可以看出平均每帧的大小位于 200Kb 以下(很多都在 10b 以下)。2000Kb 以上的帧零散存在,中心还有一张 9544 Kb(1.2MB)的帧。
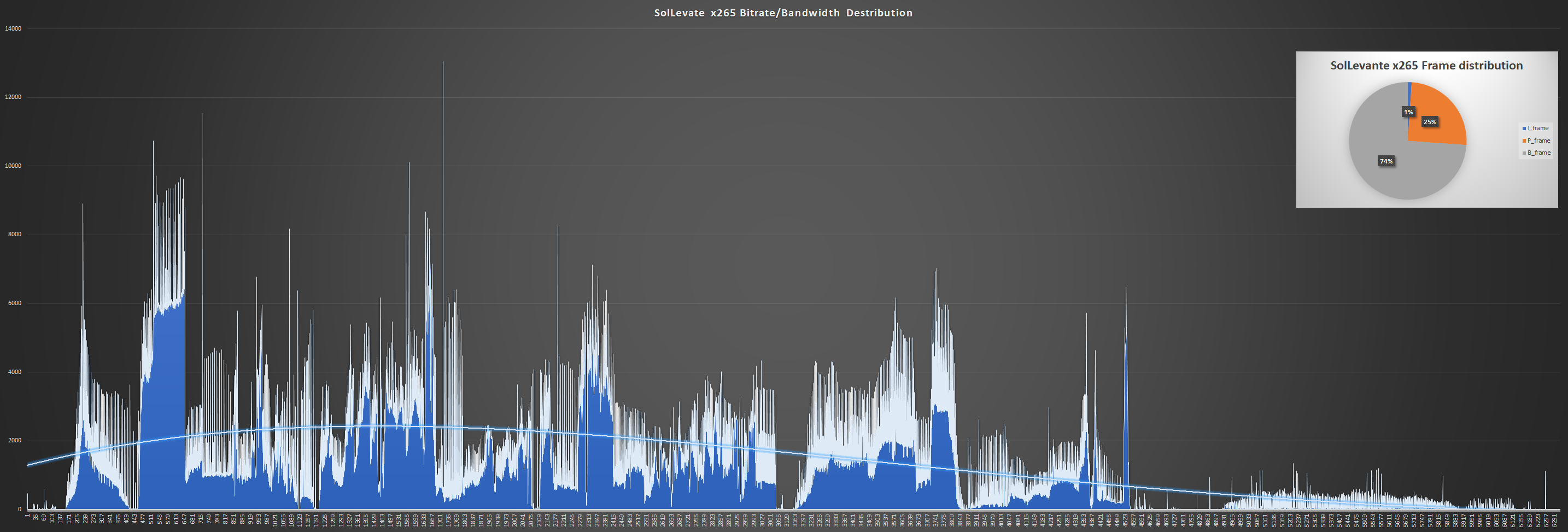
图:这段场景动态复杂的 3840x2160 视频约有 6000 帧,除了 I 帧的尖峰以外,出现了整块隆起的码率分布,左侧的复杂部分达到了 6~10Mbps。
视频编码不可能三角
一般情况下,用户希望在可接受的编码速度(fps 为单位)下,得到画质较高、文件体积较小的视频,构成了压制的不可能三角。
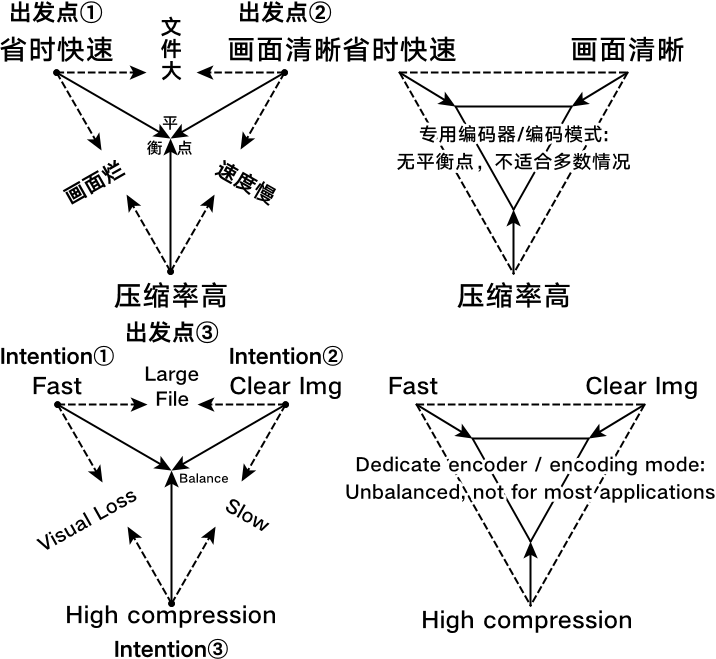
图:三种出发点构成。其“完美中心点”不一定符合当下需求,但决定了是否能满足所有情况
图:不同率控制模式权衡编码速度,画质,文件体积的能力不同,当然有的模式根本没得选
“码率分布成因”中说明了在画质高度一致时,逐帧的码率变化非常大,在网络播放时可能会因为峰值而卡顿;反过来倘若要限制码率变化/波动,则画质的一致性便会下降(或文件体积增加)。于是在选择率控制模式时,要在“两个一致”之间妥协。
“不可能三角”中说明了在速度、画质和文件体积三者此消彼长,虽然大多情况下选择兼顾三者的中心点即可,但也需要根据不同场景的要求加以偏置
率控制模式
平均码率模式(Average Bitrate、ABR)
编码器进行简易的逐帧画面分析(前瞻进程 Lookahead),基于当前编码出视频帧的码率,结合分析出未来帧的复杂度概况来断定量化值分配的策略。在压制的不可能三角中实现“体积和速度优先,忽略画质”的平均码率率控制模式,如果故意提供较高码率(如 1920x1080@30 下设置 50Mbps),则成为一种近无损模式。
- 设定统一的“平均每帧大小”(以码率每秒 / Kbps 统计)
- 编码器会根据目标平均码率和剩余帧数,粗略估算每帧可用的码率预算,只要这个平均值不超过用户设定的平均码率,就按照现有逻辑(MEMC、帧类型、块大小)设定每帧的量化强度
- P、B 帧由于运动矢量等信息依赖其他帧,通常量化强度可以更高,体积更小
- I 帧则要独立编码,体积较大,如码率紧张,I 帧可能需要更强量化(画质下降更明显)
ABR 模式优缺点
- 简单快速
- 适合内容或背景一成不变的直播场景
- 适合对传输带宽有要求,同时算力需要和其它软件共享的场景
- 难以应对画面突然变复杂的场景
- 综合的码率分配均衡性一般,依赖更频繁的转场来重设码率“经费”,或将 GOP 后半帧压缩到烂
- 如果用户设定的码率太低,ABR 模式下的画质会放飞自我,因此设置起来需要经验
全局/固定量化强度模式 Constant Quantizer
禁掉率控制,使得速度绝对优先,以生死有命、富贵在天之策而分配码率,因此几乎只适用于无损量化(QP 0)的“模式”。
- 支持直接由用户指定 I、P、B(等)帧各自的量化强度
CQP 模式优缺点
- 速度最快
- 可以通过设定最小量化值的方法跳过量化,实现一种无损压缩模式
- 码率分配不匀问题最严重,码率与文件体积不易预测
码率调谐常量模式(Constant Rate Factor、CRF)
编码器进行简易的逐帧画面分析(前瞻进程 Lookahead),为每帧算出一个量化值(QP)的模式,调谐常量值,也就是 CRF 值在其中起到范围锚定作用,从而实现倾向于画质或压缩方向的码率分配策略。CRF 是在压制的不可能三角中实现微妙平衡的率控制模式,也是追求画质优先的唯一模式(码率受限时则画质不如 2pass 模式均衡)。
- 在设定量化强度指标(CRF 参数值)的基础上,允许编码器根据当前画面的特性与帧类型进一步优化每帧的量化强度分配
- 若 CRF 值较低,而当前帧可以使用较高的量化压缩强度(如参考帧 P、B 帧)时,编码器会提高量化强度;这样不但文件体积缩小,损失的画质也肉眼难辨
- CRF 值越大,最终画质越差、码率越低;这样码率的分配仍然会是均匀的极优解
CRF 模式优缺点
- 同码率下的压缩率、画质最好,最适合用于分享和收藏高质量小体积视频素材
- 在要求实时编码的场景中可能会因为编码 I 帧考虑太多、用时过长、导致延迟丢帧
- 调整 CRF 和 CQP 模式不能直接控制文件体积,尽管这是因为“视频在这个质量下,只能压缩到这个程度”,但有时会导致用户不理解
- 在严格要求视频体积的场景中,如微信等平台会因为文件体积限制而不便于分享
- 尽管这种情况下应该用技术更先进的编码器,但因为用户、平台、手机厂商的多方因素,所以导致了视频打不开的兼容性问题
恒定码率模式(Constant Bitrate、CBR)、可变码率模式/灵活码率模式(Variable Bitrate、VBR)
- 在 ABR 或 CRF 模式的基础上启用码率缓冲区(Video Buffer Verifier、VBV)控制得到
- CRF 模式本质上属于半个 VBR 模式,ABR 模式本质上属于半个 CBR 模式;两者都依赖 VBV 限制码率峰值
- 当码率超过用户指定的 VBV 上限,则编码器自动增大量化强度,以防溢出
- I 帧后的一系列帧都会比以往大一些,造成整体的码率/文件体积上升,峰值下降
- 如果整体码率上升触发 ABR 限制,则进一步增加量化强度,画质下降,换来带宽控制,得到变化更平稳的码率分布
CBR、VBR 模式优缺点
- 可以解决峰值码率过大的问题
- 代价是整体文件体积提升(VBR),或者整体画质下降(CBR)
- 使得 CRF、ABR 模式能够更好地胜任直播、串流(外网网络播放)场景
两遍模式 2pass
- Pass 1:运行 CRF 或 ABR 模式,得出每帧的量化强度,从而得出码率分配统计
- Pass 2:运行 ABR 模式,利用第一遍采集的码率分布,事先完成所有帧的码率预分配,从而精准控制文件体积
- 尽管不同的编码器对 2pass 模式的实现有差异,但基本流程与此处一致
2pass 模式优缺点
- 解决了 ABR 模式在 GOP 前后码率分配不匀的问题
- 码率分配不匀的问题被弱化,只要最终码率类似,2pass 就能做到相当于 CRF 同码率的均匀度
- 能够精准控制文件体积(目标体积 ÷ 视频时长 = 目标码率),适用于硬性要求视频体积,还要考虑编码兼容性的场景
- 例如,一个聊天平台限制上传文件不可以超过 200MB,就是一种硬性体积要求
- Pass 2 与 Pass 1 的帧类型分布(绝大多情况下)必须完全一致,所以如转场、关键帧、前瞻进程等设置需要更改时只能重做 Pass 1
- 如果要使用高压缩,则必须在 Pass 1 就使用速度较慢动态搜索与补偿,从而使得整个流程下来的编码用时远超其他模式
- 流程复杂,故障点(Point of failure)最多,操作相对困难
常见的误解误区
- “我有硬性视频体积要求。我希望在保证一定画质的同时,将体积缩小一点,所以应该使用 2pass 模式”
- 需求类型错误,“文件不得超过 200 MB”才是真正的硬性需求
- “保证一定视频质量的同时,将体积缩的小一点”是 CRF 模式所针对的需求
- “我希望控制体积和码率,画质可以差些,但不能一会清晰一会糊,所以应该使用 CBR 模式”
- CBR 模式保证的是码率变化的一致性,但视频内容是变化的,因此使用 CBR 模式必然一会清晰一会糊
- CRF 模式的“CRF 值”能保证画质的一致性,应该使用 CRF 模式
- “我的视频要上传到视频平台,上面说达到多少平均码率后可以免二压,所以应该使用 2pass 模式”
- 所谓的免二压规则早已绝迹,视频平台一律压缩上传的视频,除非是个人搭建的网站
--ipratio --pbratio
<浮点,默认 1.4、默认 1.3>P 帧相比 IDR/i 帧,以及 B/b 帧相比 P 帧的质量偏移。默认预设是给录像视频片源用的。
- 低成本动漫/多静态画面/PPT 录屏画面:各降低 0.2
- 剪辑素材:提高 --crf,不用改这两个参数
- YCbCr 4:4:4 片源:x264 默认会自动修改 --chroma-qp-offset,不用改这两个参数
--bframes
<整数 0~16>最多可连续插入的双向参考帧 B 帧数量(超过后插入 P 帧):
- 一般录像/录屏快速,以及视频剪辑素材设3~6以防止录制和剪辑的解码算力要求过高
- 电影片源快速设8左右
- 低成本动画片源,或播放设备配置或硬解兼容高的话可设在13左右
注:--bframes > 8,同时 --keyint > 250 会根据视频分辨率而显著增加内存占用。
CRF 模式
--crf
<浮点范围 0~51,默认 23>码率调谐常量。据 cplxBlur,cutree,B 帧偏移给每帧分配各自量化强度的固定目标质量模式。素材级画质设在 16~18,收藏~高压画质设在 19~20.5,YouTube 是 23
ABR 模式(average bitrate)
--bitrate
<整数 kbps>平均码率。若视频易压缩且码率给高,就会得到码率比设定的片子;反过来低了会不照顾画质强行提高量化,使码率达标。一般推流用的“码率选项”就是设置了这个参数
CQP 模式
--qp
<整数 0~69,禁用 CRF/ABR/模式决策/率失真优化>设定全局量化强度。除非有既定目的,否则不建议使用。如果要手动指定特定范围的帧类型和量化值,则应使用 SBRC 下层模式
Zones 分段模式
手动指定帧数片段,每个片段允许指定一种上层模式和一些控制参数。
--zones
<开始帧,结束帧,参数 A,参数 B…> 手动在视频中划区,采用不同上层模式来实现如提高压制速度,节省平均码率,提高特定画面码率等用途 (一般用来"处理"片尾滚动字幕). zones 内的 me, merange 强度/大小不能超 zones 外。可用参数有 b=, q=, crf=, ref=, scenecut=, deblock=, psy-rd=, deadzone-intra=, deadzone-inter=, direct=, me=, merange=, subme=, trellis=
- 参数 b= 调整码率比率,限制
--zones内的场景使用当前 0~99999% 的码率,100% 相当于不变 - 参数 q= 即 CQP 模式的
--qp参数 - 两段式结构例:
--zones 0,449,crf=32,me=dia,bframes=10/450,779,b=0.6,crf=8,trellis=1
2pass 模式
先用 CRF 模式分析整个视频总结可压缩信息,后根据 ABR 模式的码率限制统一分配量化值。有 pass 2 给特别高的平均码率,输出最小损失的最小体积近无损模式,以及 pass2 给码率硬限的全局整体压缩模式
--pass 1
<挡位,导出 stats 数据文件>
--pass 2
<挡位,导入 stats 数据文件>
--stats
<路径,默认在 x264/5 所在目录下>设定导出和导入 stats 数据文件的路径和文件名
VBR,CBR 模式
缓冲区
带宽是有限资源。一旦网络、硬盘等带宽变慢或变卡,播放就会卡顿。因此,播放器会设置内存缓冲区,利用了传输速度有时会快于当前视频码率的随机条件,预加载一些数据以缓解卡顿。此时就简化成了“缸里一端加水、另一端放水”的问题。如此,只要平均传输带宽大于 GOP 平均码率则播放流畅了。
- 加水:数据流流入缓存,码率即流速
- 出水:数据流流出缓存
- 缸不缺水:播放不卡顿
- 缸不满盈:硬件解码不溢出缓存(类似于大型游戏溢出显存,但有些设备可能会拒绝播放)
基于缓冲区的量化控制(Video Buffer Verifier、VBV)
由编码器单独设置一个小缓冲区,观其盈缺而增加/激增量化强度,从而缓解码率波动问题。
| 网络输入 | → | [VBV 缓冲 ~4MB] | → | 解码器 | → | [解码帧缓冲 ~10MB] | → | 显示 |
| ↑ | ↑ | |||||||
| 编码器虚构,治码率波动 | 存储参考帧/待显示帧 | |||||||
- 保证
--rc-lookahead范围内,用户通过--vbv-bufsize --vbv-maxrate指定网络/设备元器件带宽所能及的缓冲速度是否大于等于码率流量 - 码率超过缓冲区域则视频必然会卡顿,所以加大视频中「码率大于带宽处」的压缩强度。因此 VBV 对画质的破坏较大
- 与 CRF 上层模式一并使用时叫可变码率 Variable BitRate(VBR),或 Capped-CRF 模式
- 与 ABR 上层模式一并使用时叫固定码率 Constant BitRate(CBR),或 Capped-ABR 模式
--vbv-bufsize
<整数 kbps,默认关(0),需小于 --vbv-maxrate ÷ 帧率>虚构缓冲区的大小,当压缩视频数据流会超出这个大小时增加量化压缩强度。有以下几种设置方式:
- 互联网直播~串流:\(\text{bufsize} = \left[\text{maxrate}, 2 \times \text{maxrate}\right]\)
- 低延迟直播(每帧都小于 maxrate):\(\text{bufsize} = \text{maxrate} / \text{fps}\)
- 高画质串流(画质仍低于关 VBV):\(\text{bufsize} = \left[4 \times \text{maxrate}, ... \times \text{maxrate} \right]\)
注:在对解码缓冲速度有要求的应用里,需要同时确保解码 GOP 缓冲时长合规,时长 = bufsize ÷ maxrate 秒。
--vbv-maxrate
<整数 kbps,默认关(0)>带宽条件(网速、池中加水速度),降低以限制带宽波峰(提高量化强度 + 强降噪)。主要限制了 I 帧的体积,直接影响 I 帧的可参考价值,反而会导致文件体积和总码率增加,画质降低(如 P 帧、B 帧内的 I 块数量增加的情况);因此如果网络带宽能够承受波动,则不建议远低于 --vbv-bufsize 。
--nal-hrd
<开关,默认关,需 VBV>开启假想对照解码器 Hypothetical reference decoder。与假想播放流程中得到额外的 VBV 控制信息,并写进每段序列参数集 sps 及辅助优化信息 sei 里,适合提高 VBV 控制精度
--ratetol
<浮点百分比,默认 1> maxrate 限码的容错程度,用于防止压缩过大,但与此同时码率过大所导致卡顿的次数会增加
下层——FTQP 模式
手动通过文件制定帧类型和量化强度。
--qpfile
<路径到文件>手动指定帧类型和量化强度 closed-gop 下 K 帧的 frame type 量化强度下层模式。qpfile 文件内的格式为"帧号 帧类型 QP"
- 帧类型可以选 [I,i,K,P,B,b]
- 大写 B 代表 B-Pyramid
- 大写 I 代表 IDR 帧
- K 在
--no-open-gop时代表 IDR 帧 - K 在
--open-gop时代表 i 帧 - x265 中,量化强度(QP 值)可以不填,代表使用上层率控制模式
- x264 中,量化强度(QP 值)填-1 代表使用上层率控制模式
qpfile.txt 例:
- 0 I 18
- 1 P 20
- 2 B 22
- 3 i 21
- 4 b 28
其它率控制
可以搭配除 CQP 以外的上下层模式使用,决定了视频各处的最终量化值
--qpmin
<整数 0~51>由于画质和优质参考帧呈正比,所以仅高压环境建议设最高 14
--qpmax
<整数 0~51>在要用到颜色键,颜色替换等需要清晰物件边缘的滤镜时,可以设26防止录屏时物件的边缘被压缩的太厉害,其他情况永远不如关 --cutree/--mbtree
--chroma-qp-offset
<整数,默认 0>AVC 规定 CbCr 的码率之和应等于 Y 平面,所以 x264 会拉高色度平面的量化。
- 使用
--psy-rd后,x264 会自动设定 -2~-4。 - 不用
--psy-rd时,动漫或幻灯片录屏片源的 4:2:0 视频可手动设 -2~-4 - 编码 YCbCr 4:4:4 时,x264 会自动设定 -2~-4。
--slow-firstpass
<开关>pass1 里自动关闭以下提速,或自动提高以下参数的强度,以保证 pass1 模式中 CRF 模式计算量化值的准确度:--no-8x8dct --me dia --partitions none ref 1 --subme <=2 --trellis 0 --fast-pskip,可手动覆盖为强度更高的参数
自适应量化(Adaptive Quantization,AQ)
一种利用感知对比度掩蔽现象的帧内分块码率调整,将更多码率分配到“更重要”处的策略。


{kind=link}
感知对比度掩蔽现象(Perceptual Contrast Masking)
注:这不是摄影后期/PhotoShop 的对比度遮罩处理法(Contrast Masking)
自然界中的动物通过打乱自身外形的线条轮廓,从而在不调整自身颜色,不改变体温,不变更习性,不妥协体型大小的情况下实现的外形伪装。这种效应的参数包括:
- 空间距离差异——两种特征的距离越近,掩蔽越强
- 特征差异——两种特征的摆放角度,空间频率越接近,掩蔽越强
- 对比度差异——两种特征的对比度越大,掩蔽越强
这种现象说明不只是音量,颜色或亮度的差异能掩蔽内容,单纯是画面中细节的分布不同就可以让人视而不见——空间频率高,纹理复杂的内容能够掩蔽频率低,纹理简单的内容,只要找出这些信息,就有机会进行更强力的有损压缩了。
主观画质理论衍生的 AQ 策略
- 自适应压缩纹理
- 纹理复杂、空间频率高的大范围区域(如砂砾、宣纸平铺)会掩蔽掉一定程度的量化失真,同时人眼对低频信息的变化更敏感——压缩纹理保平面
- 程度:量化失真处的造成的失真程度不大于纹理像素值变化的程度即可
- 要注意的是,尽管该方法常用,但对比度感知现象的原理尚不明确——如果观众仔细看就会发现失真
- 不适合漫画材质动画与 3D 动画,不适合高码率视频
- 对应
--aq-mode 1
- 自适应保护纹理
- 人眼倾向于观察人物神态、且主观上喜欢看锐利的边缘,因此要优先保纹理
- 程度:平面和暗场画面更糊一些即可,当然掩蔽效应也要利用上(仍压缩纹理,只是更轻),尝试平衡平坦区和纹理的画质
- 属于心理视觉优化(PVO)策略,可能会降低客观画质
- 不适合码率优先、非画质优先的视频
- 自适应保护纹理和暗场
- 由于画面暗部细节时有主要内容(聚焦到角色神情等可能)、暗部的变糊和色阶断裂等默认编码器压缩策略会变得不可取,因此额外给低亮度区域分配保护权重
- 程度:同上
- 属于心理视觉优化(PVO)策略,但可能会增加客观画质
- 不适合码率优先、非画质优先的视频
方差(Variance)
表示数据样本相对于整体平均值的离散程度。有时平均值,包括加权平均值指标并不可靠,或者说我们需要知道平均值到底有多可靠。因此有了这种“差→方→和→均”式计算,即“以偏差之和窥数据之衡”。
\[ \sigma^{2}=\frac{\sum_{i=1}^{N} (x_{i}-\overline{x})^{2}}{N} \]- 差:每个数据样本减去整体平均值,得到各个差值(距离)
- 方:各个差值逐一取平方以放大误差,顺便使得各个差值被绝对值化
- 在此处同样可以直接取绝对值而取平方,但这样做会失去微分兼容性,且极端值的影响更难体现出来
- 和:平方后的值求和,得到整体的平方误差/二维误差
- 均:除以样本数的平均计算,得到方差
图:实际上,“取平方”在视觉上也更加合理,例如这个 GPU 渲染流程中,上半部分使用柱状图,下半部分相同但取了平方,使得时间维度的影响偏差(视觉面积)一目了然;来源:YouTube/Threat Interactive
--aq-mode
<整数 0~3,默认 0 关闭>指定据画面分块的复杂度、CRF/ABR 模式给的逐帧量化值(QP)分化出每个画面块应有量化值的策略。
- 1方差自适应量化(AQ-Variance),适合画面内容单调、快速编码、压缩优先场景用
- 2自动方差自适应量化(Auto AQ-Variance),同时自动调整
--aq-strength的强度。推荐用于录像电影,或搭配 CRF 小于 17,高码率 ABR 等不会欠码的策略 - 3自动方差自适应量化、欠码时倾向保暗场画质(平面涂抹失真更明显)
--aq-strength
<浮点>自适应量化强度,推荐搭配 --aq-mode 使用。如动漫和幻灯片录屏等平面多过纹理的场景下 --aq-mode 1 --aq-strength 0.8, 2:0.9,3:0.7
- 录像或更复杂上如果不愿降低 CRF/增加 ABR 码率,则额外增加 0.1~0.2
- 注意低成本动漫和幻灯片录屏等平面多过纹理的画面,因此码率不足时反而要更改量化强度分配策略为妥协纹理
模式决策、环路滤镜
由于 AVC x264 的环路滤镜步骤中只有去块,所以准确的说就是“去块失真滤镜/去块滤镜(Deblock)”。之所以称作“环路/Loop”是因为编码器会在这之后进行模式决策(Mode Decision)来检查编码选用的帧内、帧间模式是否合理,于是,概念图中就出现了一条走向“倒过来回到动态搜索步骤结束为止”之后的“环路”路径,而这条路径上恰好有去块滤镜。当然,在更先进的视频编码上还有更多可用的滤镜,因此称为“滤镜组”。
环路滤镜的效果作用于重建帧(编码结果)上——成为未来帧的参考。模式决策(帧内模式、运动矢量、块划分等)都在编码当前块时完成,不会在环路滤镜处理之后再复查和修改。但编码器在决策时通常会基于“滤镜处理后的参考帧”来进行运动估计和预测,以保证和解码端一致。模式决策对于帧内编码的块/帧尤其重要,因为帧内预测的模式是根据重建(并滤波)后的左侧、左上和顶部相邻像素做的(信息有限),因此很可能还有更好的编码模式可取。对于帧间编码的块,其前后的参考帧已经进行过滤镜处理(因为编解码顺序不同于播放顺序),因此编码器可以安全地根据处理后的参考帧复查动态向量。
- 整合动态搜索与补偿可能性:
- 计算并收集每种帧内,帧间预测模式的率失真分数(见下方说明)
- 整合分块参考量化可能性:
- 计算并收集每种细分块方案(4x4,8x8,16x16),参考帧长度,量化强度下的率失真分数
- 压缩方案定制:
- 选择码率最小的压缩方案并不是最优解,因此找出率失真分数最高的方案集,得到码率与画质最为平衡的方案
去块滤镜(Deblock)
有时,率控制模式(CRF/ABR),以及宏块树(MBTree/CUTree)在分配量化值时产生的块失真(宏块间分界线)瑕疵。这有时是因为最优的量化值没找到/没来得及调优,或者画面中有难以被动态预测(动态信息随机/有时与前景交叉)、自适应量化(宏块中的内容差不多,无法重分配码率)等功能处理好的内容(如云雾/暗色动态背景等)。在 x264 的去块滤镜还未推出前,避免这种失真最直接的办法就是关闭宏块树功能,但也只是治标不治本。
去块滤镜原理
去块滤镜大体上检查了 1 像素宽或高,且临近此边缘的像素值变化不大,构成瀑布状地形的横纵边缘。去块操作的本质就是平滑滤镜,因此即使是普通强度也会降低画面整体锐度;因此,要求画面锐度高,但画质要求不高时,会有大幅降低去块强度,使得少量块失真被保留的做法。
去块滤镜本身可在多种滤镜工具及剪辑软件中直接调用,但精确处理需要动态搜索、帧内搜索来获取相关信息。不过,考虑到视频编码器在压制时大概率会引入新的块失真,所以最直接的方法是用视频编码器内置的滤镜完成这一步。
边界强度 Boundary strength
判断去块力度
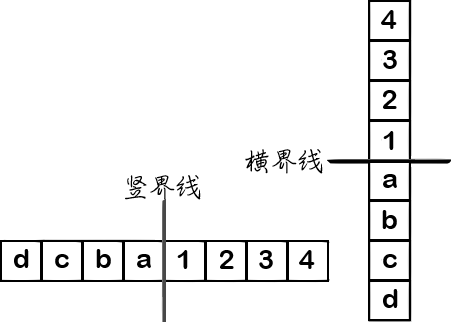
图:取最小 8x8 范围(两个 4x4 分块)间的界线举例。
- 平滑4:a 与 1 皆为帧内块,且边界位于 CTU/宏块间,最强滤镜值
- 平滑3:a 或 1 皆为帧内块,但边界不在 CTU/宏块间
- 平滑2:a 与 1 皆非帧内块,含一参考源/已编码系子
- 平滑1:a 与 1 皆非帧内块,皆无参考源/已编码系子,溯异帧或动态向量相异
- 平滑0:a 与 1 皆非帧内块,皆无参考源/已编码系子,溯同帧或动态向量相同,滤镜关
--deblock
<整数偏移值,默认 1:0。推荐 0:0、-1:-1、-2:-1> 平滑强度偏移 : 搜索精度偏移。两值于原有强度上增减。
- 平滑≥1时用以压缩
- 平滑-2~-1时略降锐度,适合串流
- 平滑2适合锐利视频源,4k 电影,游戏录屏。提高码率且会出现块失真
- 平滑-3~-2适合高码动画源/桌面录屏。增块失真,但观感仍比 1 好
- 搜索大于 2易误判;小于 1会遗漏。建议保持0~-1,除非量化强度大于 26 时设1
优化量化策略
率失真优化 Rate distortion optimization(RDO)
视频压缩策略往往会被直截了当地归纳为“低码率好”——给所有压缩步骤选择产生码率最小的编码模式(如帧内/帧间、哪种块划分、运动矢量朝向等)。这样做无异于使用 CQP 率控制模式,导致过度的有损压缩使得本可用于无损压缩(冗余)的机会被因小失大地浪费——码率分配失衡。例如,过大的量化强度会破坏 P-B 帧原本可以参考 I 帧的部分,由于差异太大,编码器只得放弃参考,把这个区域重编码为 I 块,或直接改成 I 帧,从而出现“码率增加,同时画质降低”的现象。可以说码率分配的是否均衡程度至关重要。
实现码率分配优化需要三种信息——(编码后的)失真、码率代价、(编码后的)码率。将失真,码率分别看做两种“越大越差”的程度,再根据码率代价——“此处码率的宝贵程度”缩放出一个坐标空间,问题就迎刃而解——找到码率最小,同时失真最小的编码模式即可,而“找到最小”的决策过程需要统计每个编码步骤下的多个至全部编码模式——率失真优化(RD)。
\[J = D + \lambda \cdot R\]编码器在决定采用哪种编码模式时,不再只考虑码率 R 或失真 D,而是计算所有候选模式的率失真代价 \(J = D + \lambda R\),然后选择代价 J 最小的那个模式。
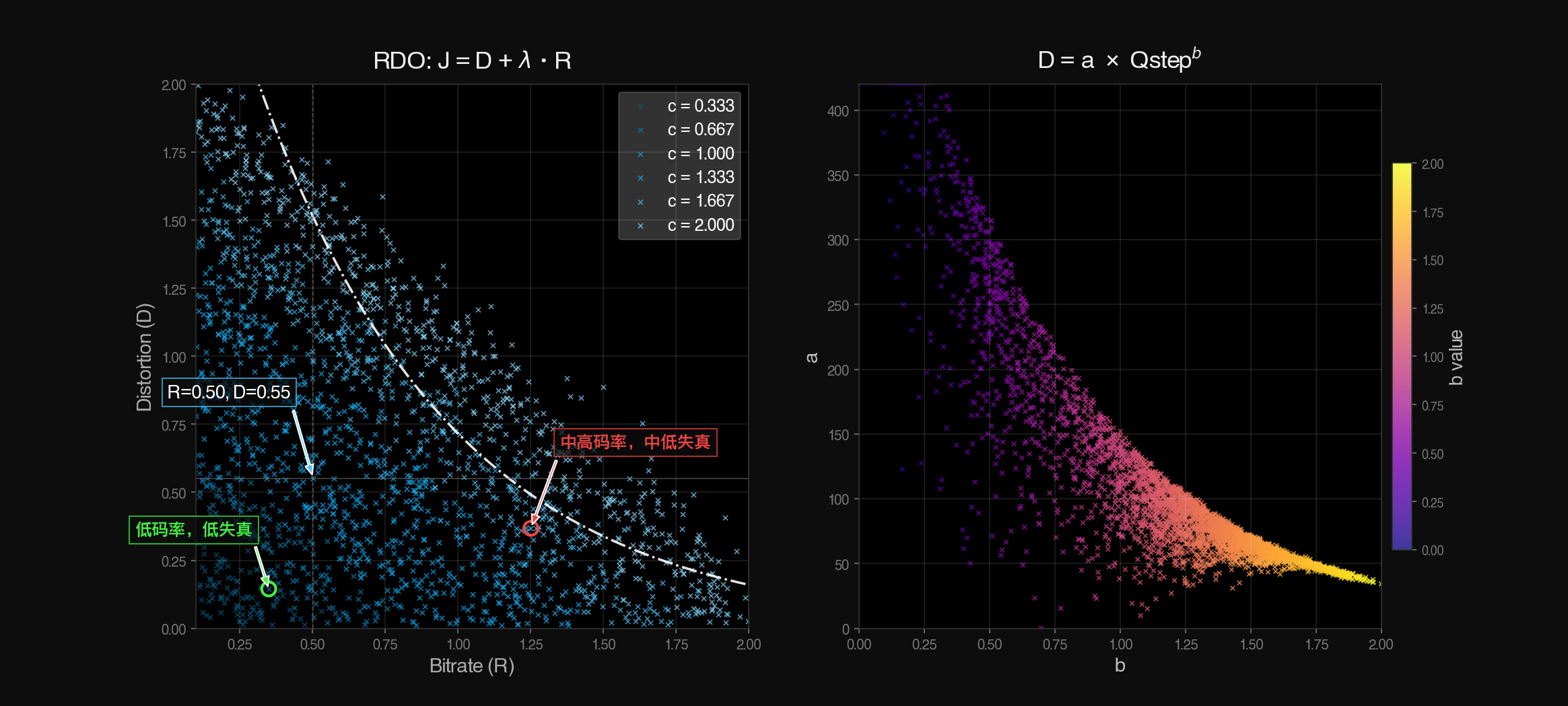
图:率失真优化中λ的斜度变化与效果(左)与不同模式决策产生的不同“×”点位(右,由随机正态分布模仿得来,仅作示意)
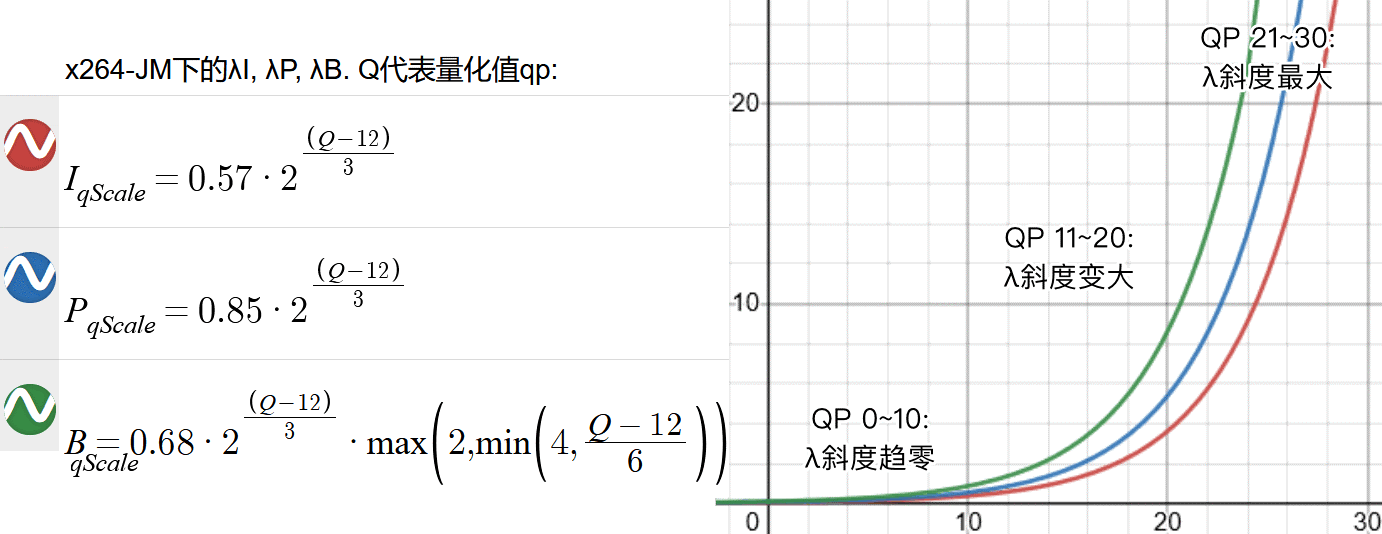
图:不同量化值(QP)对应了不同的(λ)斜度,从而定制筛选(优化)策略
从上图可以看出,选择图中尽量往左下角的数据点并不难,难点在于列举各个模式会大量占用性能,因此编码器会做更粗略,产生点位更少的率失真优化。
--fgo
<整数默认关,推荐 15 左右>将高频信号在量化前后的差距也算进率失真优化的统计中,使优化更倾向于保留细节和噪声
心理视觉优化
Psycho-visual optimization(PVO)更类似于一种自适应量化,利用人类视觉系统的特性,通过掩蔽和感知量化,实现低码画面的码率再分配,勉强保持高压缩的同时,提供更好的主观视觉质量,妥协客观质量(与输入源的差距)。
- 空间掩蔽(Spatial Masking):
- 人眼会忽略高锐度边缘周边区域的画面,因此增加这些区域的量化强度,省出码率
- 频域掩蔽(Frequency Masking):
- 突兀大范围信号会遮住不够明显、空间面积不够大的周边信号,例如彩色噪点遮住纯色线条、大亮斑遮住小暗斑,因此可以在变换块中剔除空间频率相似,但信号相异的 DCT 分量/系子,省出码率
来源:Applied Vision Research and Consulting
--psy-rd
<α:β 浮点,默认 1:0>心理学优化设置。α 保留纹理,β 在 α 的基础上保留噪点细节。画质优先时,α、β 值的大小与画面复杂度呈正比,但增加的程度相比于画面复杂度应该更小。
- 低成本动漫与幻灯片录屏画面:0.4:0.1~0.6:0.15
- 电影,录像等场景:0.7:0.12~1.3:0.2
--no-mbtree时,可将 β 设置为 0
--no-psy
<开关>若视频量化很低,纹理清楚,没有优化的必要可以关。但大部分情况下不应该关,而是用较低的优化强度

图:心理视觉优化保留高频信号,同时压缩周围和其中的非高频信号
宏块树与量化值曲线缩放 qComp
源自 libavcodec 实现同码率下整体画质更高结果的逻辑:“复杂动态场景的帧间参考少。所以分配更少码率(增加量化压缩),更多码率应该分给参考多而远的简单动态场景”。这样做在码率受到很大限制时能保护多数场景的画质,但缺点则是大多时候,动漫场景等「背景不动前景动」的场景(如人物脸部)画面被压缩太多的问题。x264 中所做的改进是“逐宏块应用这套逻辑”——即 Marcoblock Tree (MBTree)。量化值曲线缩放 quantizer curve compression 则被“贬为”控制 MBTree 等一系列量化强度分配算法中的一个缩放参数,见 desmos 互动例。
qComp 的用途
- (ABR 模式)根据宏块的数量与
--qcomp值设置初始复杂度百分比: \[ \text{Complexity} = \left( \frac{\text{Count}_{MB}}{2} \right) ×700000^{\left( \frac{qcomp}{100} \right)} \div 100 \] - 获取当前场景的长度 \( \text{Duration}_{clip} \)
- 当前帧与下一帧间的图像模糊后做 SATD,获得「模糊复杂度 \( \text{Complexity}_{blurred} \)」
- (关 MBTree 时)使用
--qcomp缩放模糊复杂度,以换算出当前帧的 qScale: \[ \text{qScale} = \left( \text{Complexity}_{blurred} \right)^{1-qcomp} \] - (开 MBTree 时)据 I 帧在当前片段的权重设单帧量化强度(基准单帧用时 ÷ 当前场景用时 × I 帧用时 ÷ 帧率): \[ \text{qScale} = Duration_{frame} \div Duration_{clip}\times Duration_{iframe} \div \text{fps} \]
--qcomp
<浮点范围 0.5~1,推荐默认 0.6>模糊复杂度 cplxBlur 以及宏块树迭代每帧量化强度范围的曲线抑制参数。越小则复杂度迭代越符合实际状况,抑制 CRF,宏块树/CU 树(MBTree/CUTree),bframes 影响的效果就越弱,搭配高 CRF 能使码率控制接近 VBV 的程度。越大则 CRF,mb-cutree,bframes 越没用,越接近 CQP
- 小于 0.5,中~强 MBTree CRF/ABR低延迟逐帧迭代qp; 画面主前景动时用,允许宏块树导致零星宏块欠码
- 0.5~0.7 中 MBTree CRF/ABR中延迟逐帧迭代qp, 画面含背景动,或混合情况用,平衡优先
- 大于 0.7 中~弱 MBTree CRF,ABR 中到高延迟逐帧迭代量化强度,保留重噪点,或 FPS/STG 游戏录屏场景用
- 小于 0.5 关 MBTree 画面不分前背景,如静态图像,PPT/桌面录屏节约性能用
- 大于 0.5 关 MBTree 动态画面,不分前背景时节约性能用
- 0(if 判定)启用固定码率模式
- 1(if 判定)启用固定量化强度模式
宏块树 Macroblock-Tree/帧间逐宏块自适应量化
宏块的构成可以被视作“帧间预测 + 帧内预测 + 预测残差”三张图。如果宏块的绝大多数内容数据(如 70%)来自于帧间预测,而这个宏块里当前 GOP 末尾(关键帧间隔 --keyint)很近了,那么它的出现时间自然是配不上它的码率的。如果找出并降低这种宏块的码率(指定该宏块的量化值/量化强度 +N),省下来的码率分给 GOP 开头和中间的宏块,码率的分配就更均衡,整个视频的画质都会提升了。宏块树就是实现这种码率分配优化的算法,本质上这是一种时间域的逐宏块自适应量化,且在现代视频编码中被重用。详见 x264 率控制算法 及 MBTree 论文。
由于宏块树的步骤位于前瞻进程(Lookahead)中,而前瞻进程位于动态搜索和动态补偿之前,且前瞻进程只使用半分辨率的视频帧,因此,此时的宏块树会额外尝试一些简单的帧内和帧间预测。
注:帧间参考代价只能小于等于帧内参考代价,类似于(同视频下的)P 帧体积不应大于 I 帧;若出现帧间参考代价大于帧内参考代价的情况,就重设为「帧间参考代价等于帧内参考代价」
宏块帧内和帧间的参考代价记为 \(\text{Cost}_{intra}\) 和 \(\text{Cost}_{inter}\),通过前瞻进程(Lookahead)中以下“搜索”步骤得到:
- 简单帧内预测/宏块自身信息量预测:尝试水平和垂直模式
- 水平模式:得到残差为 2,代价为 4
- 垂直模式:得到残差为 3,代价为 5
- 选择水平模式,记 \(\text{Cost}_{intra}\) 代价为 4
- 简单帧间预测/宏块参考信息量预测:以上一帧为参考,进行运动估计
- 运动矢量 (1,1):得到残差为 1,代价为 2
- 运动矢量 (2,2):得到残差为 2,代价为 3
- 选择运动矢量 (1,1),记 \(\text{Cost}_{inter}\) 代价为 2
- 宏块总代价:自身代价 + 上一帧帧间预测代价 \( \text{Cost}_{intra} + \text{Cost}_{inter} \)
- 上一帧帧间预测代价:上一帧的宏块与当前帧宏块匹配帧间预测模式所得的代价
- 溯块总代价:自身代价 + 下一帧帧间预测代价 \( \text{Cost}_{intra} + \text{Cost}_{propagate} \)
- 下一帧帧间预测代价:下一帧的宏块与当前帧宏块匹配帧间预测模式所得的代价 + \(\text{Propagate}_{amount}\) 累积的代价
- 由于 B 帧是双向参考帧,所以不存在「上/下一帧帧间预测代价」,而是「参考帧/被参考帧间预测代价」
- 设定:各个宏块自身代价与参考代价的比率,再从 100% 减掉这个比率,得到给其他宏块参考的信息比率 \[ \text{propagate}_{fraction}=1-\left(\frac{\text{Cost}_{intra}}{\text{Cost}_{inter}}\right) \]
- 设定:各个宏块内容传播给下游宏块的代价 = 给其他宏块参考的信息比率 × 溯块总代价
\[ \text{Propagate}_{amount} = \text{Propagate}_{fraction} \times (\text{Cost}_{intra} + \text{Cost}_{propagate}) \]
- \( \text{Propagate}_{fraction} \) 越小,传播到下游宏块的信息量就越少
- \( \text{Cost}_{intra} + \text{Cost}_{propagate} \) 越大,传播到下游宏块的信息量就越大
- 计算:从最远范围
--rc-lookahead开始,从远到近地累积所有宏块的 \( \text{Propagate}_{amount} \),作为统计列表中下一个宏块的 \( \text{Cost}_{propagate} \)- 这里非常绕,总之就是「传播到下游宏块的信息量 \( \text{Propagate}_{amount} \)」是持续更新累积的过程,而不是从当前帧往后查找传播了多少信息
- 如果出现动态位移(当前宏块的范围被切分到下帧的 4 个宏块之间时),这 4 个宏块会各自按比例拆分出各自的传播信息量
- 分配:从最远范围
--rc-lookahead开始,从远到近地根据已有的 \( \text{Cost}_{propagate} \) 和自身的信息量 \( \text{Cost}_{intra} \),通过 \( \log_{2}() \) 非线性地映射到量化强度,得到宏块树中每个宏块的量化值偏移: \[ \Delta \text{QP} = -\text{strength} \times \log_{2}\left( \frac{\text{Cost}_{intra}}{\text{Cost}_{propagate}} \right) \div \text{Cost}_{intra} \]
大部分情况下宏块树偏移的量化强度为零,因为宏块没有参考溯块信息可用。
--rc-lookahead
<帧数量,范围 1~250,推荐 keyint÷2> 指定 cutree 的检索帧数,通常设在帧率的 2.5~3 倍。高则占用内存增加延迟,低则降低压缩率和平均画质。
注:MBTree/cutree 会自动选择 --rc-lookahead 和 \( \max\left( \text{keyint}, \max\left( \text{vbv-maxrate}, \text{bitrate}\right)\div\text{vbv-bufsize} \times \text{fps} \right) \) 中最小的值作为检索帧数
--no-mbtree
<开关>关闭宏块树/CU 树(MBTree/CUTree)/帧间自适应量化,不推荐。
熵编码/文本压缩
完整的熵编码流程见 x265 教程网页版——熵编码。
霍夫曼编码(Huffman Coding)
曾经广泛应用于数据压缩的算法,虽然没有被用于 AVC,但目的相同,此处用于替代说明 x264 中高度复杂的 CABAC 算法。步骤分为:
- 统计频率:
- 在第一次遍历文本/pass1 时,只统计每个字符出现的次数,并按出现频率从小到大排序
- 构建初始节点:
- 将每个字符和其出现频率作为一个节点,并将这些节点放入一个最小堆(优先队列)
- 构建霍夫曼树:
- 从最小堆中取出两个频率最小的节点
- 创建一个新节点,其频率是这两个节点频率之和,将这两个节点作为新节点的子节点
- 将新节点插回最小堆中
- 重复上述步骤,直到堆中只剩下一个节点,这个节点就是霍夫曼树的根节点
- 生成编码:
- 通过遍历霍夫曼树,为每个字符生成霍夫曼编码。通常向左的节点表示为向 0,向右的节点表示为向 1
霍夫曼编码的例子
来源:geekforgeeks——greedy3 算法。假设第一次遍历文本得到了如下字符及其频率:
| 字符 | 频率 |
|---|---|
| A | 5 |
| B | 9 |
| C | 12 |
| D | 13 |
| E | 16 |
| F | 45 |
- 统计频率:已完成
- 构建初始节点:
- 据出字次数从小到大排序:(5,'a'),(9,'b'),(12,'c'),(13,'d'),(16,'e'),(45,'f')
- 构建霍夫曼树:
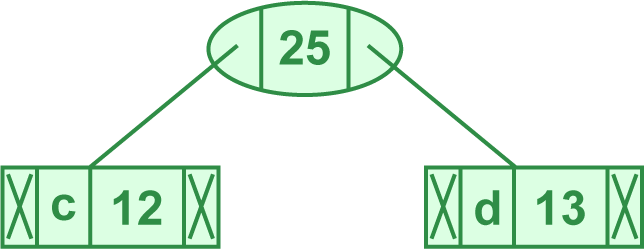
- 取出字次数最小的两个元素 (5, 'a'), (9, 'b'),合为 (14, 'ab')
- 得 (12, 'c'), (13, 'd'), (16, 'e'), (45, 'f'), (14, 'ab')
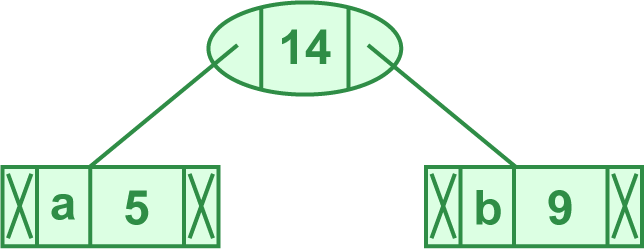
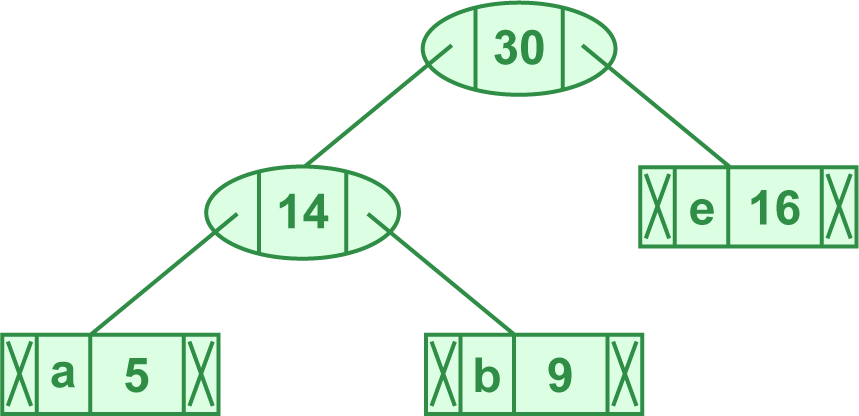
- 取出字次数最小的两个元素 (12, 'c'), (13, 'd'),合并为 (25, 'cd')
- 得 (14, 'ab'), (16, 'e'), (45, 'f'), (25, 'cd')
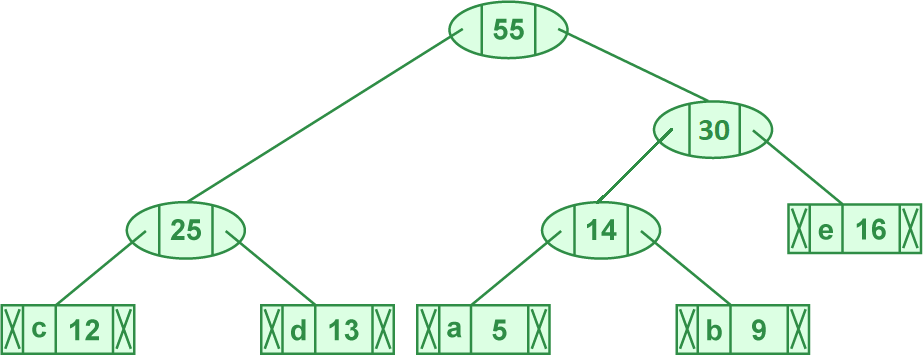
- 取出字次数最小的两个元素 (14, 'ab'), (16, 'e'),合并为 (30, 'abe')
- 得 (25, 'cd'), (45, 'f'), (30, 'abe')
- 取出字次数最小的两个元素 (25, 'cd'), (30, 'abe'),合并为 (55, 'cdeab')
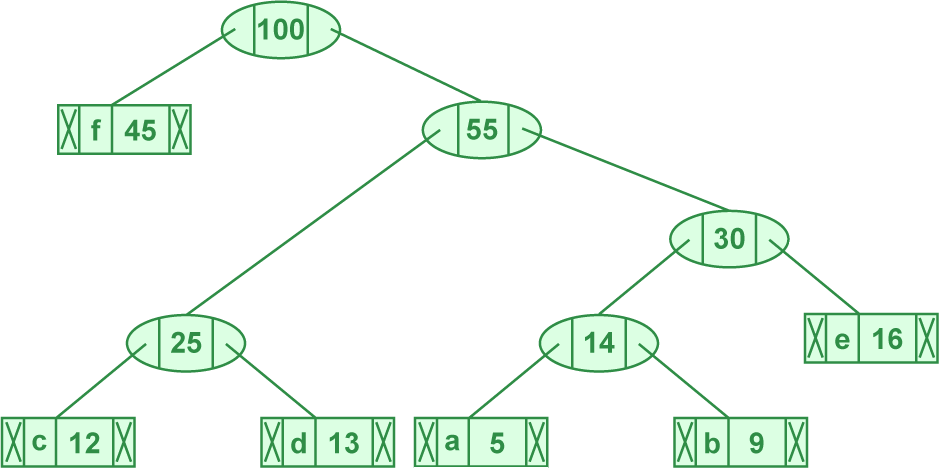
- 得 (45, 'f'), (55, 'CDEAB')
- 取出字次数最小的两个元素 (45, 'f'), (55, 'cdeab'),合并为 (100, 'fcdeab')
- 得 (100, 'FCDEAB')
- 取出字次数最小的两个元素 (5, 'a'), (9, 'b'),合为 (14, 'ab')
- 生成编码:
- 从霍夫曼树根节点开始,为每个字符生成霍夫曼编码:
| 字符 | 编码 |
|---|---|
| F | 0 |
| C | 1-0-0 |
| D | 1-0-1 |
| A | 1-1-0-0 |
| B | 1-1-0-1 |
| E | 1-1-1 |
熵编码是一种无损压缩(例如代码和小说都是文本,文本编码不可更改其内容)。因此,不同的熵编码算法之间就只有编码速度和压缩率两个判断标准。
--no-cabac
<开关,不推荐>关闭 CABAC,使用 CAVLC
优化熵编码
残差 DCT 系子
Residual DCT coefficients 代表变换后量化前,已知经过量化后会被抹除的 DCT 系子。DCT 变换的例子见本教程的 变换——DCT 变换 部分。总之就是与“残差块”无关,只是都叫做残差而已。
编码块标记 CBF
Coded block flag 会被标在预测和/或与其相应的变换单元(亮度块加色度块)中表示该单元是否附有较多的残差系子:CBF=1 代表有、0 代表没有。引导四叉树 quadtree 算法进一步分枝——宏块向下分块。详见 US9749645B2。

图:四叉树的分块。见维基百科
DCT 归零优化(DCT Decimate)
由上可知,录像与电影片源中的动态噪点会直接干扰编码器的分块,导致熵编码总是要处理系子数量少的 8x8,4x4 分块,而 x264 设计时面向了 640x480 分辨率的视频,所以就有了专门用于避免无效分块,避免性能和熵编码压缩率被浪费的系子归零处理(现已淘汰但默认开启)。具体是评估整个 16x16、8x8 或 4x4 块的能量,如果该块的整体残差数据耗费的码率与视觉收益不成正比则将整个块的系数全部抛弃(归零)。
--no-dct-decimate
<开关,默认关>关闭 DCT 变换的低强度系子归零操作,以减少细节损失,降低有损压缩。适合幻灯片录屏等画面极其干净,或经过大量滤镜过滤噪声,--crf < 17或 ABR --bitrate > 500000 编码策略的源视频
死区量化器 Dead-zone Quantizer 优化
死区,也叫 dead-band,neutral-zone,或无作用区,代表输入到输出波形中可归零的部分。

图:信号死区设 0.5 时,输入到输出 y=x 波形的变化。见维基百科
死区量化器的用途同上。x264 中,--trellis没有完全开启(2)时,死区量化器会被替代启用。默认设置下:
- 帧间亮度块中,分量为 -21~21 的 DCT 系子归零
- 帧内亮度块中,分量为 -11~11 的 DCT 系子归零
- 优化后的块回到原来的编码步骤——量化中
因此,结果是在高分辨率下,默认设置对画面细节的涂抹较强,所以一般建议 --trellis 2,或在最少大于等于 1600x900 分辨率、--trellis < 2 的时候更改死区量化器相关参数的默认值。
--deadzone-inter
<整数 0~32,默认 21,--trellis 小于 2 时开启>一种逻辑简单的帧间再量化——细节面积小于死区就删掉,大就保留。一般用途建议 8,高画质建议 6
--deadzone-intra
<整数 0~32,默认 11,--trellis 小于 2 时开启>一种逻辑简单的帧间再量化——细节面积小于死区就删掉,大就保留。一般用途建议 8,高画质建议 4
软判决率失真游程走线优化——SDQ trellis
Soft decision quantization / SDQ trellis 算法。通过限制量化后块中的 DCT 系子 coefficients 强度,甚至偏移当前系子的强度值到临近系子,以保证游程编码中走线的平稳。过程中由率失真计算确认对画面的影响符合预期质量,从而提高压缩率。--trellis 应用于量化步骤之后,并且对少数突兀的 DCT 系子强度做了平均化,所以叫“再量化”。详见 x265 教程——优化熵编码
--trellis
<整数,范围 0~2, 推荐 2>软判决优化 CABAC 的率失真再量化。
- 1调整模式决策 mode decision 处理完的块,快速压制用
- 2同时调整帧内帧间参考和分块完成的块,效果最好
色彩信息
(重复上述科普内容)物理亮度:可见光电磁波的强度或振幅,以流明 lumen/lm,坎德拉/烛光量 candela/cd,或尼特 nits/cdm2 计量:\(1 {nit} \approx 3.426 \text{lm}\)。
高动态范围 High Dynamic Range HDR
原本是高端音响的标准,代表最小音量下没有一点电流噪声,最大音量可以和真实场景媲美的性能。与扬声器的大小和材质是否匹配场景相关,即「重硬件轻软件」。因为只要硬件达到 HDR 1000 规格,那么只要调高亮度就可以了;而随便一个中位水平的电视/显示器/手机屏幕亮度都能达到 HDR 400 标准。
HDR 信息分为硬件、软件、以及数据,共 3 类不统一的标准。为保证色彩正确,压制时应额外检查并确保与视频源的一致性。如:
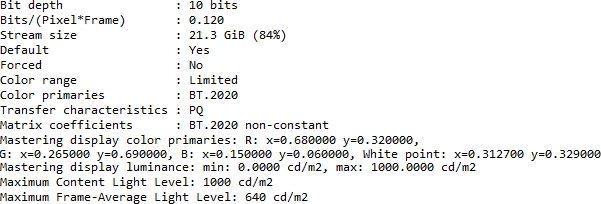
图 1: cll 1000,640. master-display 由 G(13250…) 开头,L(10000000,1) 结尾
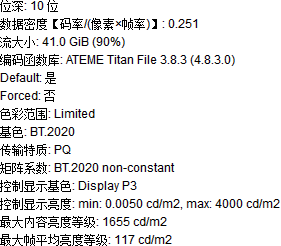
图 2: cll 1655,117/L(40000000,50)/colorprim bt2020/colormatrix bt2020nc/transfer smpte2084
--master-display
<G(x,y)B(,)R(,)WP(,)L(,)(绿,蓝,红,白点,光强)>写进 SEI 信息里,告诉解码端色彩空间/色域信息用
- HDR 标准设立时还没有 HDR 电视,所以就把 master-display 写成必须参数了,而最重要的信息反而是 cll。
- 绿蓝红 GBR 和白点 WP 指马蹄形色域的三角 + 白点 4 个位置的值×50000
- 光强 L 的单位是 candela×10000
- SDR 视频的 L 是 1000,1。压制 HDR 视频前一定要看视频信息再设 L,见上图
- DCI-P3 电影业内:G(13250,34500)B(7500,3000)R(34000,16000)WP(15635,16450)L(?,1)
- bt709:G(15000,30000)B(7500,3000)R(32000,16500)WP(15635,16450)L(?,1)
- bt2020 超清:G(8500,39850)B(6550,2300)R(35400,14600)WP(15635,16450)L(?,1)
- RGB 原信息 (对照小数格式的视频信息,然后选择上面对应的参数):
- DCI-P3:G(x0.265,y0.690),B(x0.150,y0.060),R(x0.680,y0.320),WP(x0.3127,y0.329)
- bt709:G(x0.30,y0.60),B(x0.150,y0.060),R(x0.640,y0.330),WP(x0.3127,y0.329)
- bt2020:G(x0.170,y0.797),B(x0.131,y0.046),R(x0.708,y0.292),WP(x0.3127,y0.329)
Video Usability Information(VUI 元数据)
VUI 是元数据,播放器会读取这些元数据来选择特定的色彩空间播放视频,由于 HDR 视频的标准受到厂商竞争割据等因素,用户需要手动指定 HDR 参数到 VUI 中才能正确播放(不过,有时电视厂商会为了节省成本而只读取一小部分信息,如只读取 MaxCLL 和 MaxFall)。
光强/光压 Candela 等于尼特,即 \(1 \text{cd} = 1 \text{nit}\)。因 bt601,709,HDR-PQ,HLG 标准重视的亮度范围,曲线所异(偏亮或偏暗),故需要量化曲线,心理学优化,模式决策的重适配。
--cll
<最大内容光强,最大平均光强>压制 HDR 源一定照源视频信息设,找不到不要用,见上图例。
播放条件
--range
<full/limited,默认留空>指定视频源的色深范围,full:完整,limited:有限。剪辑时应额外检查剪辑软件的输出设定一致性。
--chromaloc
<整数 0~5,默认留空>指定色度像素相对于缩小前画面的采样位置,涉及到解码端的色度像素对齐。如果源视频标注,则建议标注。
- 0 ←(left)
- 1 中(center)
- 2 ↖(topleft)
- 3 ↑(top)
- 4 ↙(bottomleft)
- 5 ↓(bottom)
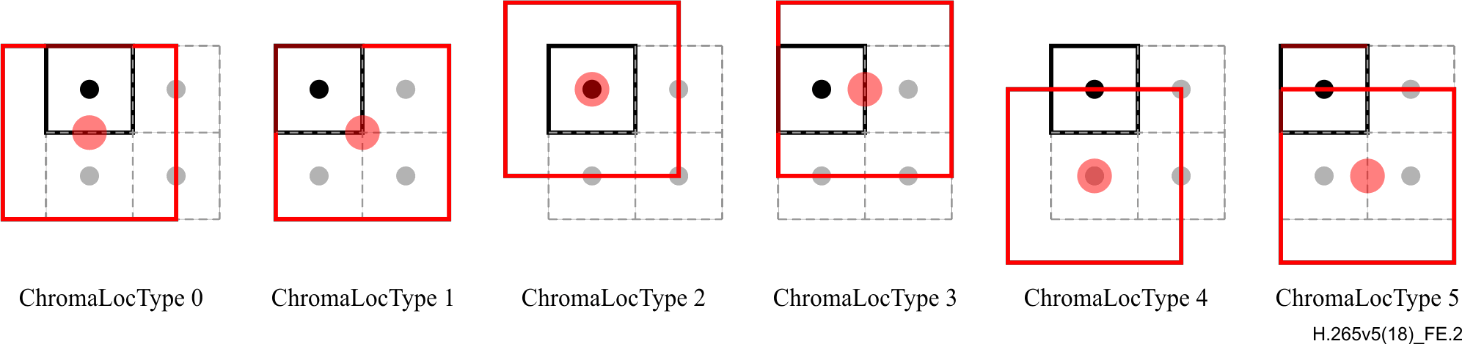
图:色度采样位置
图:国际电信联盟(ITU-T)H.265 Figure E.1(第 384 页) 沿用了 H.264 Figure E.1(第 443 页) 的色度采样位置,与上图所述一致,但更难看懂。
--colorprim
<字符>原色色系:bt470m,bt470bg,smpte170m,smpte240m,film,bt2020,smpte428,smpte431,smpte432。
--colormatrix
<字符>矩阵格式:fcc,bt470bg,smpte170m,smpte240m,GBR,YCgCo,bt2020c,smpte2085,chroma-derived-nc,chroma-derived-c,ICtCp。
注:不支持 bt2020nc
--transfer
<字符>传输特质:bt470m,bt470bg,smpte170m,smpte240m,linear,log100,log316,iec61966-2-4,bt1361e,iec61966-2-1,bt2020-10,bt2020-12,smpte2084,smpte428,arib-std-b67。
上方 HDR 部分图 2 的“PQ”字样即 st.2084,所以参数值为 smpte2084。
预设参数
--preset
<ultrafast/superfast/veryfast/faster/fast/medium/slow/slower/veryslow/placebo>见下:
| 参数\预设 | ultrafast | superfast | veryfast | faster | fast | medium | slow | slower | veryslow | placebo |
|---|---|---|---|---|---|---|---|---|---|---|
| b-adapt | 0 | 默认 1 | 2 | |||||||
| bframes | 0 | 默认 3 | 8 | 16 | ||||||
| direct | 默认 spatial | auto | ||||||||
| me | dia | 默认 hex | umh | tesa | ||||||
| merange | 默认 16 | 24 | ||||||||
| partitions | none | i8x8,i4x4 | 默认 p8x8,b8x8,i8x8,i4x4 | all | ||||||
| rc-lookahead | 0 | 10 | 20 | 30 | 默认 40 | 50 | 60 | |||
| ref | 1 | 2 | 默认 3 | 5 | 8 | 16 | ||||
| subme | 0 | 1 | 2 | 4 | 6 | 默认 7 | 8 | 9 | 10 | 11 |
| trellis | 0 | 默认 1 | 2 | |||||||
| weightp | 0 | 1 | 默认 2 | |||||||
| no-weightb | 1 | 默认 0 | ||||||||
| no-8x8dct | 1 | 默认 0 | ||||||||
| no-cabac | 1 | 默认 0 | ||||||||
| no-deblock | 1 | 默认 0 | ||||||||
| no-MBTree | 1 | 默认 0 | ||||||||
| no-mixed-refs | 1 | 默认 0 | ||||||||
| scenecut | 0 | 默认 40 | ||||||||
| no-fast-pskip | 默认 0 | 1 | ||||||||
| slow-first-pass | 默认 0 | 1 | ||||||||
--tune
<字符串>更改 preset 的一些参数,见下:
- zerolatency 集中算力到一次编码一帧,并尽可能关闭率控制和 B 帧功能:
--bframes 0 --force-cfr --no-MBTree --sync-lookahead 0 --sliced-threads --rc-lookahead 0
- grain 保留高频信号/最高画质:
--deblock -2:-2 --psy-rd <跳过>:0.25 --aq-strength 0.5 --no-dct-decimate --deadzone-inter 6 --deadzone-intra 6 --ipratio 1.1 --pbratio 1.1 --qcomp 0.8
- animation 优化动漫场景画面:
--ref <若当前设定大于 1 则乘以 2> --bframes <当前设定值 +=2> --deblock 1:1 --psy-rd 0.4:<跳过> --aq-strength 0.6
- fastdecode 降低解码算力占用以降低超高帧率——分辨率解码负载
--no-deblock --no-cabac --no-weightb --weightp 0
- film 优化录像与电影场景画面
--deblock -1:-1 --psy-rd <跳过>:0.15
- stillimage 优化静态图像画面
--deblock -3:-3 --psy-rd 2.0:0.7 --aq-strength 1.2
- psnr 减少编码前后内容的均方差(MSE)变化/失真(客观画质),同时关闭率失真优化的心理学优化功能(降低客观画质,提升主观画质)
--aq-mode 0 --no-psy
- ssim 减少编码前后内容的结构性变化/失真(客观画质),同时关闭率失真优化的心理学优化功能(降低客观画质,提升主观画质)
--aq-mode 2 --no-psy
线程控制
任务拆分
视频编码会对大量数据进行复杂计算,属于高吞吐量(High throughput)程序,多线程优化在这里包括将编码的大步骤拆分为独立的小操作,例如通过将一个帧拆分为粗分块(宏块)来实现。不过,拆分是有极限的;x264 r1607 前的版本曾有过逐条带(slice,一组宏块)的编码任务拆分,目的是通过大量条带的并行提高编码单帧的速度,降低延迟。但压制后的效果非常差,因为:
- 熵编码中,CABAC(见 x265 教程——熵编码)因为上下文不连续所以经常重设,效果大打折扣
- 动态信息的动态向量长度被限制到条带分片内部,干扰动态补偿,降低压缩率
- 帧内冗余降级为条带内冗余,降低帧内编码压缩率
- 增加了相当一部分(多余条带与 NAL 封包的)文件头
同步与异步
将一个复杂的大步骤拆分,会产生适合同步(Synchronous)与适合异步(Asynchronous)执行的小步骤。例如“打印”这个操作适合异步执行;如果使用同步操作,那么打印时电脑会停止响应,等待打印完成并同步打印结果,再恢复响应,显然是不合适的。在视频编码中,除了前瞻进程(Lookahead)以外,其它的搜索与冗余步骤高度相关,因此,x264 编码器默认会占用 --threads 加 --lookahead-threads条进程,从而占用一个数量相对合理的线程数。而 --threads 达到并超过 16~24 时,可以看到画质下降一点,以及在更多核心的电脑上出现“吃不满”的问题,这就是 x264 编码特性所致的优化极限了。
码率分配均衡程度
故意创建比电脑处理器更多的线程会导致码率增加,画质降低。这是因为 CPU 一次只能运行线程数量的任务,结果就是从数量上冲淡了一些关键步骤所需的“运行占用百分比”,甚至有时等不到就跳过,最终导致了不够合理的码率分配,以及其副作用。
x264 并没有对多路/多 CPU 节点电脑优化,但 x265 使用线程池 实现了。
--threads
<整数,建议保持默认(等于 CPU 线程)>由于参考帧步骤要等其之前的步骤算完才开始,所以远超默认的值会因为处理器随机算的特性而降低参考帧的计算时间,使码率增加,画质降低,速度变慢
--non-deterministic
<开关,默认关,推荐开> 降低多线程完算性——减少多线程共享数据的可靠性,些微提高画质。使用后每个进程的冗余判断更为独断,且让新的动态搜索线程得知「旧动态搜索线程线程实际搜索过,而非参数设定」的区域。「完算性」一般仅代表通过完整计算得到结果,而不是提前跳过的计算特征。而启用多线程,VBV 都会降低完算性
--lookahead-threads
<整数,建议保持默认(应该是 --threads 的 1/4)>指定前瞻进程占用的线程数,速度太快则其后的编码进程跟不上,太慢则其后的编码进程要等结果,所以不需要改动
--frame-threads
<整数,建议保持默认(自动)>指定 --threads 中分配多少线程给编码帧,决定一次同时编码多少帧(量化,优化,帧内预测,熵编码)。剩下则是上下游的处理(连续 B 帧推演,SEI,完算性错误管理),后者占用较少
--sliced-threads
<开关,默认关,推荐关>逐条带分配多线程。x264 r1607 前的多线程分配机制,后来因为问题太多而改成了逐帧分配多线程
退一步讲,只要一个程序能吃满全部 CPU 核心,那么多线程优化自然会到位。因此,对于多线程优化一般的程序,只要多打开几个,并限制每个程序的线程数,就能提高最终的效率。例如 Windows 批处理提供的 START 命令实现异步并行(多开些编码),搭配上述的 --threads 命令限制每个编码的进程数实现。
x264 默认的前瞻线程数(--lookahead-threads)一般为计算线程数(threads)的 1/6
x264 内置滤镜
降噪滤镜
--nr
<整数 0~65536,降噪范围 100~1000,不推荐>当 ABR/VBV 指定了高于 --qpmax 或默认最大量化强度时,会调用这个滤镜。如果有降噪需求则建议使用效果更好的外部滤镜工具,或至少使用 --vf hqdn3d 滤镜
AviSynth 滤镜
--vf
<crop:[←],[↑],[→],[↓]/pad: [←],[↑],[→],[↓]/resize:[宽,高],[变宽比],[装盒],[色度采样],[缩放算法/select_every:步,帧,帧…]/hqdn3d:[空域 Y 降噪强度],[空域 C 降噪强度],[降噪时域 Y 强度],[时域 C 降噪强度]/yadif[模式],[顺序]>裁剪,加边,缩放/更改分辨率,删除/保留视频帧,降噪,色彩空间转换滤镜。例:
- crop:3,4,5,6:视频左,上,右,下分别裁剪 3,4,5,6 个像素
- pad:0,7,8,9,,,255,255,255:视频上,右,下分别加 7,8,9 个像素的 #FFFFFF(白)边
- pad:,,,,1920,1080,1,36,38:视频对称加减边到 1920x1080 像素,若加边则加 #013638(深蓝绿)边
- pad:,,,,3840,2160,,,:视频加减边到 3840x2160 像素,若加边则加 #000000(黑)边
- resize:1060,1080,96:53,,,lanczos:1920x1080 视频的宽使用 lanczos 算法缩小 53/96;同时标记视频宽在播放时,宽度应拉伸 96:53 倍(96:53 长方像素),显示为 1920x1080
- resize:1280,720,,i444,spline:使用样条插值缩放输入视频到 1280x720,储存为 YCbCr 4:4:4
- resize:1060,1080,,width,i420,lanczos:使用 lanczos 插值,只将宽 width 缩放到 1060px,储存为 YCbCr 4:2:0
- hqdn3d:0,0,3,5:仅开启时域降噪滤镜,分别在 Y,C 平面设定强度 3,5
- vflip:左右翻转视频
- subtitles:在集成 VSFilter64.dll 动态链接库的情况下渲染字幕文件,需
--sub导入字幕文件,然后使用--vf subtitles参数渲染字幕到视频 - select_every:5,0,1,3,4:视频每 8 帧中留第 1,2,4,5 帧,丢弃第 3 帧
- AviSynth 中主要用于搭配 IVTC 滤镜使用,但 x264 中没有这些滤镜
- yadif:1,tff:使用 bobbing 算法,上场优先模式将交错视频转为逐行视频
这些滤镜可以在实现简单的画面处理。使用多个滤镜的例子如:--vf crop:10,0,10,0/resize:640,480,,,,lanczos。
- resize 中 [select_every] 滤镜详见 AviSynth Wiki
- resize 中 [色彩空间] 可用的值有:i400,i420,yv12,nv12,nv21,i422,yv16,nv16,yuyv,uyvy,i444,yv24,bgr,bgra,rgb
- resize 中 [缩放算法] 可用的值有:fastbilinear,bilinear,bicubic,experimental,point,area,bicublin,gauss,sinc,lanczos,spline
- yadif 是一种简单的交错转逐行滤镜,推荐用画质更好的外部滤镜,见附录 ε:交错转逐行与 IVTC
- x264 中内置的 yadif 滤镜来自 MPlayer,因此参数不同于 AviSynth:
- yadif 中 [模式] 可用的值有 0,1,2,3;[顺序] 可用的值有 tff 和 bff
- hqdn3d 是一种简单快速的时域 + 空域降噪滤镜。仅指定
--vf hqdn3d则使用默认强度(仅开启滤镜)为 4,3,6,4.5
--sub
<路径到文件,需 --vf subtitles 和 VSFilter64.dll>见 --vf subtitles 说明